


Google Cloud Text-to-Speech
Last year, Google launched its high-fidelity text-to-speech synthesizer, which can read the text in 20 different languages in hundred plus custom voices. Cloud Text-to-Speech leverages Google’s own successful research in deep neural networks as well as DeepMind’s WaveNet technology. With this API, developers can quickly integrate TTS for any application that requires voice interaction. WaveNet has achieved naturalness above 4.0 in the 5-scale MOS (Mean Opinion Score) tests, which is almost in the near vicinity of actual human speech. This makes it possible for Google to provide an amazing experience when using Google Translate, Google Talkback, etc. Like me, now you might start wondering when the phone rings if the person on the other end is actually a person. Check Google TTS audio samples here. Main features of Google Cloud Text-To-Speech:- Multilingual - 20+ languages and more on the way.
- WaveNet Voices - Access to natural-sounding WaveNet voices.
- Text & SSML Support - Add pauses, numbers, and so on with SSML tags.
- Speak Rate Tuning - Speak four times faster or slower.
- Pitch Tuning - Change the pitch to 20 semitones more or less than the default.
- Volume Control - Raise or lower the output volume up to 16db or -96db respectively.
- Audio Format Flexibility - Support for mp3, Linera16, Ogg Opus, etc.
- Audio Profiles - Optimize for speaker type like headphones, phone lines, etc.
Google Cloud TTS Pricing
Google TTS API is charged monthly depending on the number of characters that are synthesized. There are two options available: Standard voices and WaveNet voices. Up to 4 million characters and 1 million characters are free per month for Standard and WaveNet voices respectively.
Amazon Polly
Amazon Polly has been around since 2016. Then, in 2018, Amazon launched a plugin to support Wordpress, kicking off its ascendency. It reached new heights with the introduction of the Amazon Echo product lines and the digital assistant Alexa. In May 2018, Amazon gave Alexa developers access to eight different voices via Polly to enhance their Alexa skills. Integration is simple and quick and can be accessed via the Polly API (and various language-specific SDKs), AWS Management Console, and AWS command-line interface. In addition to the fluid pronunciation of text that enables the delivery of high-quality voice output, Amazon Polly also offers dozens of lifelike voices across a variety of languages. Just last week, Amazon introduced Zeina, a natural-sounding female voice as their first Arabic voice. The popular language-learning platform Duolingo is powered by Amazon Polly. (I haven’t gone anywhere with the two languages that I was picking up from Duolingo. But that’s just my fault, not Polly’s!) Check out Amazon Polly here. Key features of Amazon Polly:- Lifelike Voices - Fluid pronunciation to deliver high-quality natural-sounding voices.
- Unlimited Replays - Allows unlimited replays in mp3, OGG formats.
- Real-Time Streaming - Send text via API and get immediate speech.
- Customization - Adjust volume, pitch, rate, etc., with lexicons and SSML tags.
- Low cost - Pay-as-you-go, low cost per character and unlimited replays.
Amazon Polly Pricing
Amazon Polly offers a pay-as-you-go model, where the billing is done monthly for the number of characters purchased. There is even a free tier, which includes 5 million characters per month for the first 12 months, starting from your first request for speech. That’s 60 million characters a year for you to synthesize. Roughly translated, you can get as many as 625,000 free words per month.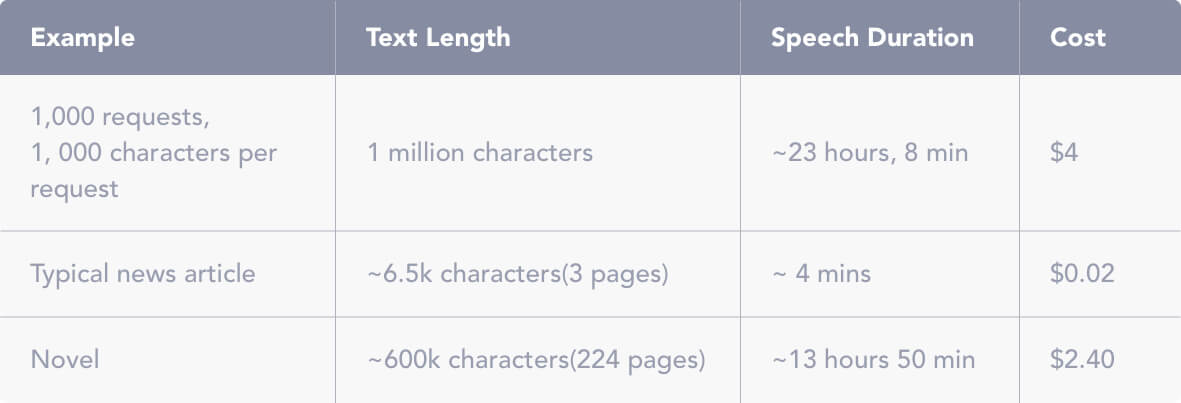
Acapela Box
Acapela Group is a European leader of voice solutions providing support and services for different platforms/ecosystems through their cloud solution, language-specific SDKs, off-the-shelf tools and services. The acapela-box is one such solution/service that converts text to an audio file online, by using the high-quality TTS voices by Acapela Group. It supports more than 25 languages with a wide variety of voices, including some that are considered premium. Acapela-box’s growing repertoire includes four new children voices (two French and two Norwegian) - Elise, Valentin, Emilie, and Elias. It went so far as to infuse cheer into standard voice. (My brain just flashed back to the iconic Joker portrayed by the late Heath Ledger in “The Dark Knight” and his immaculately delivered dialogue, “Let’s put a smile on that face”. Do you think Acapela said “Let’s put a smile on that voice” when they thought of this?) We can customize the rate of speech and tone to get the desired effect. Another interesting option is the availability of the pronunciation editor, which would enable the user to change the pronunciation of the word using phonetic transcriptions. One caveat with Acapela-box is that it has a size limit of 10,000 characters for the text conversions. Longer texts would have to be broken down into shorter ones and then synthesized separately.Acapela Pricing
The pricing for most of the solutions provided by Acapela is categorized into two: one involves annual subscription and the other is a royalty-bearing agreement depending on the number of units on the voices and the languages used. The cloud solution offers two different payment options: Peak Plan and Yearly Plan. These are based on VaaS Units (VU), where a VaaS Unit corresponds to 20 seconds of listening to a sound file. Peak Plan starts at 1500 Euros and Yearly Plan starts at 1800 Euros. The acapela-box, however, has a prepaid credits-based pricing model. According to Acapela, listening to text is free but the price for downloading a text as a sound file depends on the length of the text and the type of voice chosen.Microsoft Azure TTS
Microsoft has its own set of AI-powered Cognitive Services. Its Speech Service, powered by neural networks, is one such offering. In 2018, Microsoft announced their first neural text-to-speech service to make the computer voices similar to actual recordings of people. Azure TTS leverages deep neural patterns to replicate the natural patterns of speech, in which stress and intonation are key factors, which makes it suitable for a range of speech-driven applications. With supervised training, unsupervised pre-training, and robust neural model design, Azure has been able to enhance the voice quality since their launch. Check samples on Azure TTS website. In addition to the voices available, you can customize the voice model to provide a unique voice to your product. Maybe it’s time to rope in Neil deGrasse Tyson or Morgan Freeman to voice your opinion! Key features of Microsoft Azure TTS:- Multilingual - Supports over 45 languages in 75+ voices.
- Enhanced Voice Quality - Voices sound more natural and robust.
- Accelerated Runtime Performance - Near real-time runtime results.
- Greater Service Availability - Data centers across the USA, Europe, and Asia.
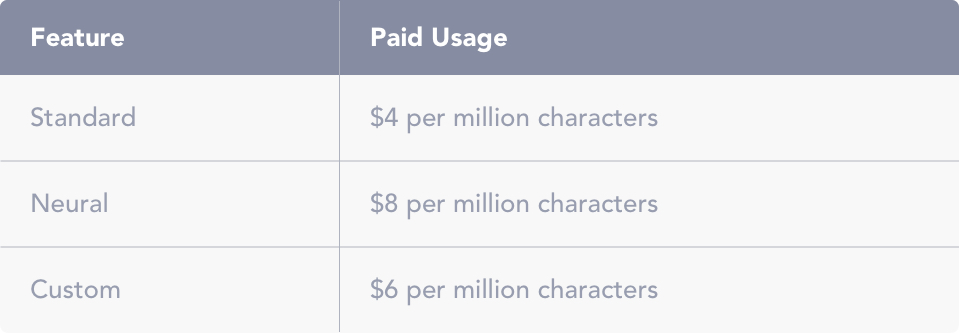
Azure TTS Pricing
Top TTS Software at a Glance
A high-level comparison of these different TTS solutions based on languages supported, voices offered, and pricing is provided below.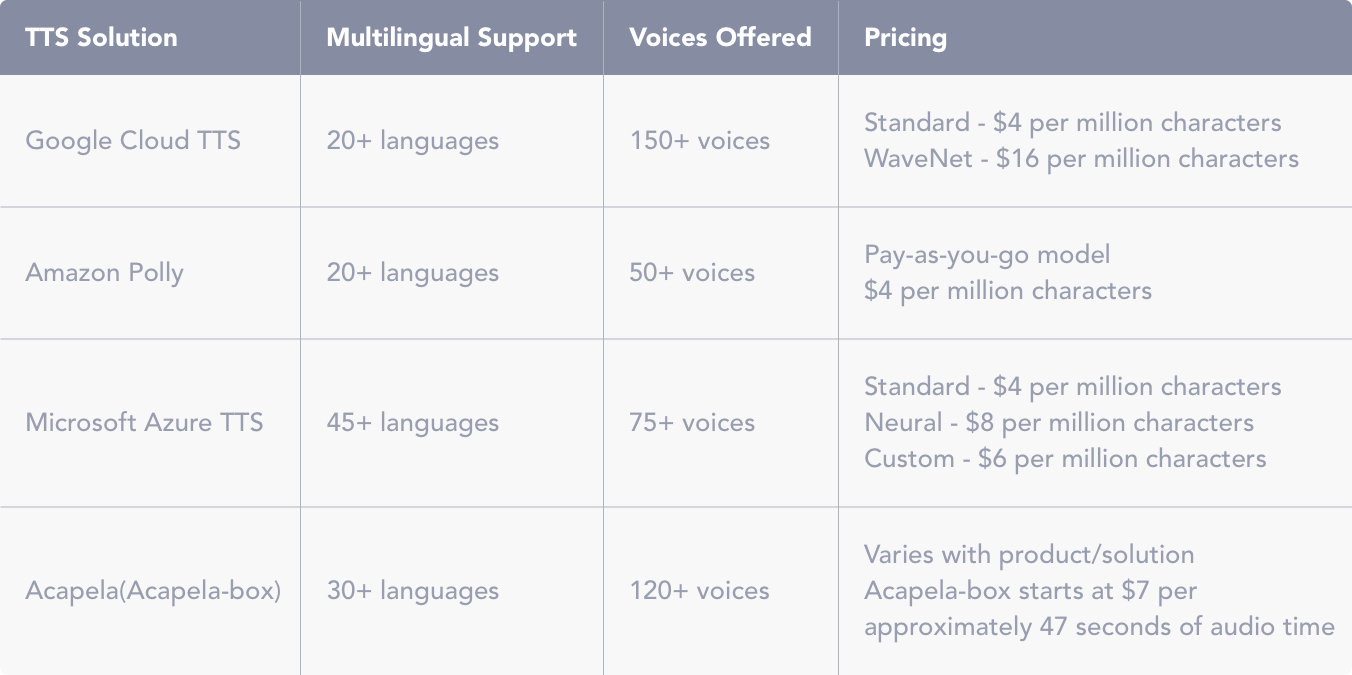
Other TTS Solutions
There are a number of other options available in the market, including open source text-to-speech solutions.- ReadSpeaker - An established online text-to-speech API with high-quality voices. It offers 200+ voices in 50+ languages.
- MaryTTS - An open source, multilingual TTS synthesis platform written in Java. With 10 languages supported out of the box and toolkits for quickly adding support for new languages, it’s worth exploring.
- eSpeak - An open source software using a “formant synthesis” method, which allows many languages to be provided in a small size. Unlike Google Cloud TTS and Amazon Polly, etc, it is not natural sounding.
- Mimic - A fast, light-weight TTS engine developed by Mycroft.AI and VocaliD based on Carnegie Mellon University’s FLITE software. Mimic is low-latency and has a small resource footprint.