


Artificial Intelligence (AI) powers several business functions across industries today, its efficacy having been proven by many intelligent applications. Of the lot, chatbots are perhaps the most well-known. From healthcare to hospitality, retail to real estate, insurance to aviation, chatbots have become a ubiquitous and useful feature. But how are these chatbots created? Let’s take a look at the architecture of a conversational AI chatbot.
AI Chatbot Framework
Regardless of the use case for which it is built, a chatbot’s basic objective is the same: find and return the information a user has requested or assist them with a task. This framework can be easily customized for specific tasks and industry requirements.
We use a framework built on top of Rasa and BERT. Rasa is an open-source machine learning framework for building contextual AI assistants and chatbots in text and voice. BERT is designed to pre-train deep bidirectional representations from the unlabeled text. It provides contextual embeddings to represent a word. Contextual embeddings consider the context in which a word appears. For example, consider these two sentences:
I went to the bank.
I sat on the river bank.
The word bank has a different meaning in both sentences. Irrespective of the contextual differences, the typical word embedding for ‘bank’ will be the same in both cases. But BERT provides a different representation in each case considering the context. A pre-trained BERT model can be fine-tuned to create sophisticated models for a wide range of tasks such as answering questions and language inference, without substantial task-specific architecture modifications.
Modular Architecture
The chatbot architecture consists of smaller modules: a Natural Language Understanding (NLU) toolkit, a dialog management system, an FAQ retrieval system, and a document search module. Before diving deep into each of these modules, let’s have a look at the workflow.
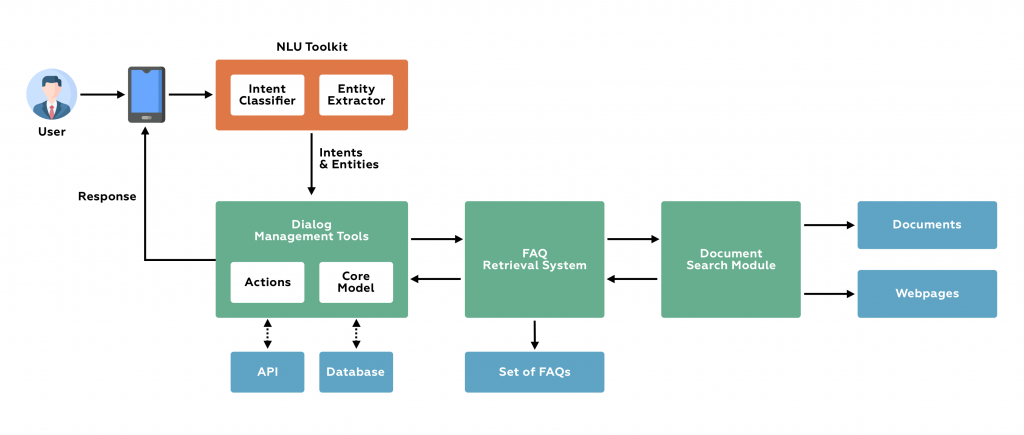
When a chatbot receives a query, it parses the text and extracts relevant information from it. This is achieved using an NLU toolkit consisting of an intent classifier and an entity extractor. Next, it responds to the user. The dialog management module enables the chatbot to hold a conversation with the user and support the user with a specific task.
A BERT-based FAQ retrieval system is a powerful tool to query an FAQ page and come up with a relevant response. The module can help the bot answer questions even when they are worded differently from the expected FAQ.
Even after all this, the chatbot may not have an answer to every user query. A document search module makes it possible for the bot to search through documents or webpages and come up with an appropriate answer. Each component is powerful on its own. When combined, they make a more capable chatbot.
Now let’s have an in-depth look at each component.
Conversational Chatbot Components
Natural Language Understanding (NLU) Toolkit
This part of the pipeline consists of two major components—an intent classifier and an entity extractor. The intent classifier understands what the user’s intention is. Is the user engaging in small talk? Do they want to know something in general about the company or services or do they want to perform a specific task like requesting a refund? The intent classifier understands the user’s intention and returns the category to which the query belongs. Typically, it selects one intent out of many. More sophisticated bots can identify multiple intents in a message.
The entity extractor extracts entities from the user message such as user location, date, etc. Rasa NLU is one such entity extractor (as well as an intent classifier). When provided with a user query, it returns the structured data consisting of intent and extracted entities. Rasa NLU library has several types of intent classifiers and entity extractors. You can either train one for your specific use case or use pre-trained models for generic purposes.
For the user query ‘What is the weather today?’, the NLU tool will structure it into {“intent”:”ask_weather”, entities:[{“date”: ”today”}]}.
Dialog Management Modules
Once the user intent is understood and entities are available, the next step is to respond to the user. The dialog management unit uses machine language models trained on conversation history to decide the response. Rather than employing a few if-else statements, this model takes a contextual approach to conversation management.
Dialog management tools make it possible to ask questions to gather additional information without deviating from the context. The conversations will be lively and more human-like. For example, a restaurant search bot would need to know about the user's preferences to find them a suitable restaurant:
User: Hello
Bot: Hey! How can I help you?
User: Help me find a restaurant
Bot: Which cuisine do you prefer?
User: I prefer Indian
Bot: Do you prefer a restaurant with outdoor seating?
User: Yes
Bot: All done! Restaurant XYZ in the 7th lane is suitable for you!
With the help of dialog management tools, the bot prompts the user until all the information is gathered in an engaging conversation. Finally, the bot executes the restaurant search logic and suggests suitable restaurants.
In Rasa Core, a dialog engine for building AI assistants, conversations are written as stories. Rasa stories are a form of training data used to train Rasa's dialog management models. In a story, the user message is expressed as intent and entities and the chatbot response is expressed as an action. You can handle even the situations where the user deviates from conversation flow by carefully crafting stories. When the user message is mapped to an intent, an action is executed. The dialog engine decides which action to execute based on the stories created.
For example, the story for normal greeting is:
* greet
- utter_greet
* bye
- utter_goodbye
Here "greet" and "bye" are intent, "utter_greet" and "utter_goodbye" are actions.
The action can be of two types—utterance action and custom action. Utterance actions are templates that a bot can directly respond with. They help the chatbot engage in hearty chitchat with the user. For example, you can create templates like “Hi, how can I help you?” or “Bye! Take care.” When the user greets the bot, it just needs to pick up the message from the template and respond. The “utter_greet” and “utter_goodbye” in the above sample are utterance actions.
Custom actions involve the execution of custom code to complete a specific task such as executing logic, calling an external API, or reading from or writing to a database. In the previous example of a restaurant search bot, the custom action is the restaurant search logic.
FAQ Retrieval
The NLU-based dialog management system mentioned earlier is powerful on its own and is sufficient to create a good chatbot. But it has a few limitations. Consider a chatbot for restaurant reservations. It has two subtasks: suggest a restaurant and book a restaurant. These require only two intents, so it is relatively easy. What if it has multiple sub-tasks such as classifying intent and writing stories? Then it becomes complicated. For example, if the user wants to know more about a particular restaurant before making a reservation, like “Does this restaurant serve tuna salad in the evening?” the above architecture cannot provide that. We can’t create intents, entities, and stories wide enough to cover the features of every restaurant in town and everything that the user might ask.
For a task like FAQ retrieval, it is difficult to classify it as a single intent due to the high variability in the type of questions. A chatbot based on predefined intents cannot handle complex queries. You need a knowledge base and an efficient method to query it. We propose a BERT-based approach to FAQ retrieval for this.
If the initial layers of NLU and dialog management system fail to provide an answer, the user query is redirected to the FAQ retrieval layer. Here the user’s query is first matched with the provided set of FAQs. If it fails to find an exact match, the bot tries to find the next similar match. This is done by computing question-question similarity and question-answer relevance. Assume that we have a set of frequently asked questions and answers. The similarity of the user’s query with a question is the question-question similarity. It is computed by calculating the cosine-similarity of BERT embeddings of user query and FAQ. Question-answer relevance is a measure of how relevant an answer is to the user’s query. FIne-tuned BERT model is used for calculating question-answer relevance. The product of question-question similarity and question-answer relevance is the final score that the bot considers to make a decision. This score is computed for every FAQ in the set. The FAQ with the highest score is returned as the answer to the user query.
Document Search
If the bot still fails to find the appropriate response, the final layer searches for the response in a large set of documents or webpages. It can find and return a section that contains the answer to the user query. We use a numerical statistic method called term frequency-inverse document frequency (TF-IDF) for information retrieval from a large corpus of data. Term Frequency (TF) is the number of times a word appears in a document divided by the total number of words in the document.
TF(x) = (Number of times term x appears in a section) / (Total number of terms in the section)
Inverse Data Frequency (IDF) is used to find the weight of words across all sections in the corpus. It determines how important that word is for the corpus.
IDF(x) = log(Total number of sections / Number of sections with term x in it)
TF-IDF value is the product of TF and IDF. For example, consider a corpus with 1000 sections. For a section containing 100 words, if the word “chatbot” appears 5 times, the TF value = 5/100 = 0.05. Now assume that the word “chatbot” appears 10 times in the entire corpus of 1000 sections. IDF value = log(1000/10) = 2. The TF-IDF value of ’chatbot’ for the section = 0.05*2 = 0.1.
The TF-IDF value increases with the number of times a word appears in a section and is limited by its frequency over the entire document. The TF-IDF values of each section in which the word appears are computed. This helps in retrieving the section in which the word appears the most.
Additional Components
Apart from the components detailed above, other components can be customized as per requirement. A human handoff can be added as the final layer if required. User Interfaces can be created for customers to interact with the chatbot via popular messaging platforms like Telegram, Google Chat, Facebook Messenger, etc. A custom UI can also be created if necessary. Cognitive services like sentiment analysis and language translation may also be added to provide a more personalized response.
Customization Is Key
The chatbot architecture I described here can be customized for any industry. For example, an insurance company can use it to answer customer queries on insurance policies, receive claim requests, etc., replacing old time-consuming practices that result in poor customer experience. Applied in the news and entertainment industry, chatbots can make article categorization and content recommendation more efficient and accurate. A car dealer chatbot can guide buyer decisions through model comparison. With a modular approach, you can integrate more modules into the system without affecting the process flow and create bots that can handle multiple tasks with ease.