

Video tracking applications are becoming commonplace with a growing number of use cases such as perimeter surveillance, asset tracking, medical imaging, and traffic violation monitoring. One of the problems that a developer must tackle while building a video tracking application is server overload.
A typical CCTV camera captures a minimum of 30 frames per second. Processing a single frame takes more than a second in a typical i5 CPU. Thus it takes 30 seconds to process frames generated in one second. This results in server overload as frames pile up for processing. Reducing the processing time is a solution, but that would require high-end expensive computational units like GPU or TPU.
Another way to handle this problem is to process only those frames that are relevant to the application. Separating such frames by quantifying the difference between frames can solve the scalability issue. By using this value, we can decide if two images are similar or not. Further down in my post, I’ll explain how we did this for an asset tracker application.
Traditional Approaches
There are many statistical methods to compute the similarity between two images. This includes Mean Squared Error (MSE), Structural Similarity Index Measure (SSIM), and Feature Similarity Index Measure (FSIM). These methods involve computing pixel-pixel differences and are purely mathematical. They are useful for detecting some broad changes.
Deep Learning Approaches
Deep learning networks leave room for a lot of customization, so we can develop a model that solves our exact problem.
- Distance Computation Using Feature Vectors—This method involves extracting features of images using a deep learning network and computing the similarity between them. The feature vector is a numeric representation of the features in the image. The images are passed through the network and the feature vectors obtained are compared using any distance computation method like euclidean distance or cosine distance. The deep learning network for feature extraction may be any network like MobileNet, ResNet, or EfficientNet. The pretrained models of these networks are available in Tensorflow Hub. Using the pretrained models gives decent accuracy but leaves no room for customization to detect the changes that are relevant to the application.
- Siamese Networks—Siamese networks take in two or more input images, pass them through a series of convolutional layers, and generate the feature vector of each image. As in the previous approach, the feature vector is then compared using a distance computation method like euclidean distance or cosine distance. The input images are passed through the same network with shared weights as indicated in the diagram below. The idea is that similar images will yield similar feature vectors. This means that the distance between the vectors is also smaller. To quantify mistakes made by the model during the training, loss functions such as binary cross-entropy, triplet loss, and contrastive loss are used.
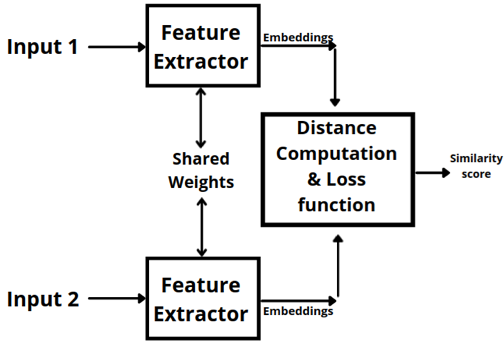
Applying Siamese Network in Asset Tracking
We wanted to build an automated asset tracker that would help us monitor assets such as mobile phones, tablets, and testing devices in a device room. The application would identify both the people entering the device room and the devices that are being removed/replaced.
For the application, only the images where a person enters the device room are relevant. But for tracking purposes, images would be taken every n second, most of them duplicate and irrelevant. To reduce the overload, similar images were removed using a simple MobileNet based siamese network. The siamese network had four major components: input layer, CNN for feature extraction, similarity function, and loss function.
Input Layer
Three images were selected as the input to the network. This triplet input consisted of a reference or anchor image, an image similar to it (positive image), and an image different from it (negative image).
The first two images shown above are similar except for the slight differences in lighting. In the application, similar images are produced more frequently. We eliminated those using the siamese network. The third image, with a person in it, is relevant to our application. After the training, the distance between feature vectors of similar images would be lesser than those of dissimilar images. Using triplets as input helped us get a better model in terms of accuracy using a small dataset. We required only around 2000 triplets to train the model.
Feature Extraction Layer
An integral part of a siamese network is the feature extraction layer that generates embeddings to represent relevant features in the image. The feature extraction layer can be any convolutional neural network that gives the embedding representation as output. We chose MobileNet as the base network because of its short inference time and high accuracy. We used the pretrained feature extractor model from the TensorFlow hub as the starting weights. Starting the training from pretrained weights helped the siamese network converge faster. From the input images, the feature extractor generated embeddings for each image (a vector with size 1280). In each epoch, the model weights were adjusted in such a way that the embeddings of similar images were similar and different images were different.
Loss Function (Triplet Loss)
The mistakes made by the model were analyzed using a loss function. The loss function expresses how far off the mark the computed output is. In this case, we used the triplet loss function, which compares positive and negative images to the anchor image. To compute the distance between feature vectors of the triplets, we used cosine distance. Triplet loss is computed as loss = max(d1 - d2 + threshold, threshold) where d1 = distance between positive image and anchor image and d2 = distance between negative image and anchor image. A threshold was added to the difference of distances to prevent loss from being 0 when both distances are equal.
A typical threshold value is 0.2. The triplet loss value decreases when the distance between the anchor image and the negative image increases and the distance between the anchor image and the positive image decreases. To adjust the weights of the network and reduce loss value, Adam was used as the optimizer.
Model Output and Impact on Server Load
The final output of the model consisted of embeddings of the input image The similarity between image pairs is high if the cosine distance value is close to 0. The input image pairs are different if the cosine distance between their embeddings is close to 1. In this way, we could extract the relevant frames. And by adding the above network to the pipeline, we could reduce server load by 70%.
Using this siamese network, developers can eliminate redundant frames without missing out on any relevant changes. The reduced number of input frames will lighten the infrastructure load and make the system capable of processing important requests without delay.