


Modality refers to how a particular subject is experienced or represented. Our experience of the world is multimodal—we see, feel, hear, smell and taste things. Multimodal deep learning tries to link and extract information from data of different modalities. Just as the human brain processes signals from all senses at once, a multimodal deep learning model extracts relevant information from different types of data in one go.
Consider the sentence, “That's just what I needed today!”. Without any context, it would be hard to make out if it’s a positive or sarcastic statement. The person’s tone of voice or facial expression can give us a clue. Multimodal deep learning tries to make use of this additional context in the learning process. In this post, I will be discussing some common approaches for solving multimodal problems with the help of a case study on document classification.
In multimodal learning, information is extracted from multiple data sources and processed. Data is essentially a collection of different modalities. Multimodal learning can manifest itself in different ways, for instance:
- Input is one modality, output is another—Take the case of an image captioning task. The machine learning model has to generate meaningful captions when it is provided with an input image. The input modality is the image and the output modality is text (caption).
- Multiple modalities are learned jointly—In the e-commerce example I mentioned above, multiple modalities such as video, audio and text are learned together.
- One modality assists in the learning of another—A known modality can help in the learning of another modality that is not so well-researched. For example, sound is understudied compared to other modalities like image or text. For learning sound representations in a better way, visual data can be used during training. SoundNet is one such architecture that uses object and scene distribution from videos to assist the learning of sound representations.
Challenges in Multimodal Learning
Multimodal deep learning promises to be the way forward in improving the performance of deep learning models. Why then are we not using it as often as unimodal networks? That question takes us to the challenges in multimodal learning.
- Different representations—A key challenge is learning how to represent multimodal data in such a way that different modalities complement each other. Each of the modalities (be it image, text, or sound) has a different representation. Image is represented as a matrix of numbers, text as discrete sparse vectors, and sound as a continuous waveform. As the representation for each of the modalities is different, building a model which can comprehend all these representations is a challenge.
- Noisy and missing data—Availability of multimodal data is another constraint. For example, we may have an abundance of image or text data, but only a small portion of images have a corresponding text description. Another problem is noisy data. For example, in a Flickr dataset, we have images and corresponding tags. It may be about the content of the image. But sometimes it could also be about the camera used to capture the image. Such information may not be relevant to the machine learning model.
- Alignment—Another challenge is to identify the direct relations between data of different modalities. For example, if we need to create a multimodal dataset for a recipe generation problem, we may want to align the steps in a recipe to a video showing the dish being made. To solve this challenge, we need to measure similarity between different modalities and deal with possible dependencies and relationships.
- Fusion—Information from different modalities have to be fused to perform a prediction. Information coming from different modalities have varying predictive power and different noise levels. For example, in audio-visual speech recognition, the visual description of the lip motion has to be fused with the speech signal to predict spoken words.
How Can We Solve These Multimodal Learning Problems?
There are a few things that we can do to get around these problems.
- Training multimodal embeddings from scratch—One approach is to create multimodal embeddings directly using networks that take in multimodal data. Many supervised and unsupervised approaches have been proposed for this. These use layers of Boltzmann machines as an autoencoders to recreate raw data. But most of them are customized for a specific task and corresponding data modalities, so there is less scope for generalization.
- Fusion of unimodal embeddings—Another approach is the fusion of pretrained unimodal embeddings. This is simpler as single modality problems are well-researched and pretrained single modality models are easily available. Single modality data is more abundant than multimodal data. One way to tackle the challenges in multimodal learning is to pretrain single modality networks on the corresponding datasets and combine them at a higher or more abstract level to create a multimodal representation. We can use embeddings to combine the features from pretrained models.
- Pretraining—In simple terms, pretraining is initializing weights from a network that we trained previously. While training a neural network, you may initialize it randomly or pretrain it and use its weights to start the training. For example, if we have a classification model that is trained on the large ImageNet dataset, it might have learned lots of features about images. Though the downstream task might be different, many low-level features will still be useful, such as edge and shape filters for images while training a new network. Pretrained unimodal networks can be used as a base to form multimodal networks.
- Embeddings—Embeddings are just a way to represent data. In deep learning, embeddings usually mean a high dimensional space where each piece of data is a vector. We could use a neural network to take in this piece of data and create a corresponding vector in an embedding space. We could also design a neural network that takes in embeddings as an input. In general, we can use embeddings to switch between modalities. For example, in an English to French language translation problem, sentence embeddings are used. There is a model that takes in English sentences and returns corresponding sentence embeddings. These sentence embeddings are then fed into a language model trained in French to generate French sentences. Similarly, we can also use embeddings to convert between modalities. We can have embeddings for image, text, or audio and we can use these embeddings to convert to another modality at a higher level of meaning. The idea is to create a shared representation that is capable of holding information from different modalities jointly.
Approaches for Multimodal Fusion
Various learning architectures are currently used for multimodal machine learning. Networks like RBMs and autoencoders are commonly used in multimodal learning. For each of the challenges discussed above, there are different methods.
The following approaches are commonly used for multimodal data fusion:
- Early Fusion—This method combines multimodal data at the data-level or input-level. There are many approaches for data-level fusion. One is to concatenate data by removing correlation between two modalities. Another is to combine data at its lower-dimensional common space. There are many statistical methods to get this done, like Principal Component Analysis (PCA), Canonical Correlation Analysis, and Independent Component Analysis.
- Late Fusion—In this method, multimodal fusion occurs at the decision-level or prediction-level. This method is similar to the prediction fusion of ensemble classifiers. The results/predictions from individual unimodal networks are combined at the prediction level. Different rules like Bayes rules, max-fusion, and average-fusion efficiently combine the output.
- Intermediate Fusion—In this method, data fusion may occur at any of the stages of training between input and final prediction. Input data is converted to high-dimensional feature vectors through multiple layers. Different modalities can be fused into a single representation layer all at once or gradually using one or more modalities at a time. This shared representation is then given to the subsequent layers.
Multimodal Document Classification: A Case Study
Document classification task concerns itself with assigning categories to different documents. In the unimodal approach, only the text is used to train and evaluate the models. But the document layout holds a big clue as to which category each document belongs. For example, the layout of a resume is way different from that of an email or a news article. If we can use the visual attributes of the document along with the text content, the performance of the document classification model could improve. We decided to compare the performance of unimodal and multimodal document classification models using the intermediate fusion approach described above.
Dataset
We worked with Tobacco3482, a dataset of images of 10 different classes of documents: advertisements, emails, forms, letters, memos, news, notes, reports, resumes, and scientific papers. The corresponding OCR-based text content is open-sourced. We selected 3308 image-text pairs for training and testing the networks (3000 for the training set and 308 for the test set).
Evaluation Metrics
The performance of unimodal and multimodal document classification models is assessed based on accuracy. Accuracy measures the percentage of correct predictions in total predictions.
Text-based Model
A neural network architecture based on BERT and LSTM was chosen for text-only document classification. The base version of the BERT model (English Uncased) with 12 hidden layers (L), 768 hidden sizes (H), 12 self-attention heads (A) and 30522 words dictionary (vocab size) was selected. The classification model had the BERT layer as the first layer. The output of the BERT layer was passed to a Long Short-Term Memory networks (LSTM) layer. LSTMs are a special kind of RNNs. A fully-connected layer and two dropout layers were also added.
Text-only Document Classification
For unimodal training, a classification layer was added to the above BERT-based network. The network was then trained using the text data from the prepared dataset. The model was then evaluated on the prepared test set. It had an accuracy of 86.52%.
Vision and Text-based Model
We used a BERT-based model to extract relevant features from the text. To extract relevant features from the document layout, a computer vision network is required. We used a CNN based on InceptionV3 architecture to learn and extract image features. We had individual unimodal networks for image and text. The next step was fusion, and for this an intermediate fusion approach was chosen. A concatenation layer was added to merge the image features by the inception model to text features by the BERT-based model. This layer creates a vector of fused features.
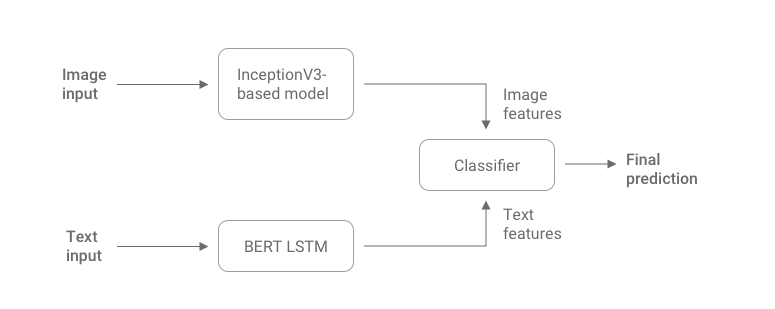
The InceptionV3 model’s last layer is the Dense layer. For the BERT-based model, the last layer is LSTM. A multimodal network was formed by fusing the features from individual unimodal networks. The outputs were brought into the same shape and concatenated to form the fused vector. After the concatenation layer, dense layers were added to form a classification head, which outputs the final result.

Stochastic Gradient Descent (SGD) was the optimizer used and cross-entropy was the loss function. After training the model using the image-text dataset, the test accuracy was 94.5%. Adding images to the text classification resulted in an almost 8% accuracy increase.

Conclusion
Multimodal learning is capable of improving the performance of deep learning models on various tasks. As seen in the document classification example discussed above, adding relevant information from another modality can help the model better understand the data. Though it’s often limited by the challenges discussed, more research is happening in the field and it clearly is going to be the next big thing in deep learning.