


Manual data entry presents a serious bottleneck for organizations that have a vast number of documents to process. With the coming of age of intelligent data extraction and document processing technologies (computer vision, natural language processing, machine learning, robotic process automation, etc.), they can now avail solutions that halve the labor and double the speed.
There are two major steps involved in intelligent invoice processing: text extraction from invoices and information extraction from the extracted text. We will cover these steps in a two-part series based on the intelligent invoice processing solution we built for a client.
The Requirement
Our client wanted to automate their reimbursement claims processing so as to ease the burden on their accounts team and reduce settlement time. Due to cost and data privacy concerns, they didn't want to go with a third-party SaaS solution. So we built a custom AI-based application that can extract the required information from PDF and image-based invoices with diverse templates.
OCR Selection
One of the major decisions we had to take at the outset was regarding the OCR engine. We weighed the benefits of PaddleOCR versus TesseractOCR and decided to go with the former for the following reasons:
- PaddleOCR could detect almost all the text present in the invoices compared to TesseractOCR.
- Most times, the text recognized by PaddleOCR was more accurate.
- PaddleOCR has lightweight models that support server and mobile. So based on the requirement, it can be deployed either as a mobile application or on a server.
- In CPU machines, the native model of PaddleOCR is slower but quantized versions of PaddleOCR models have a comparable speed. We went with a quantized version for better inference time.
- PaddleOCR provides the option to train your own custom models for new languages and new datasets of images like ID cards.
- There is an active open-source community providing support for new languages and additional features like table recognition and key information extraction.
Here's a quick visual comparison of the text extracted by PaddleOCR and TessaractOCR.

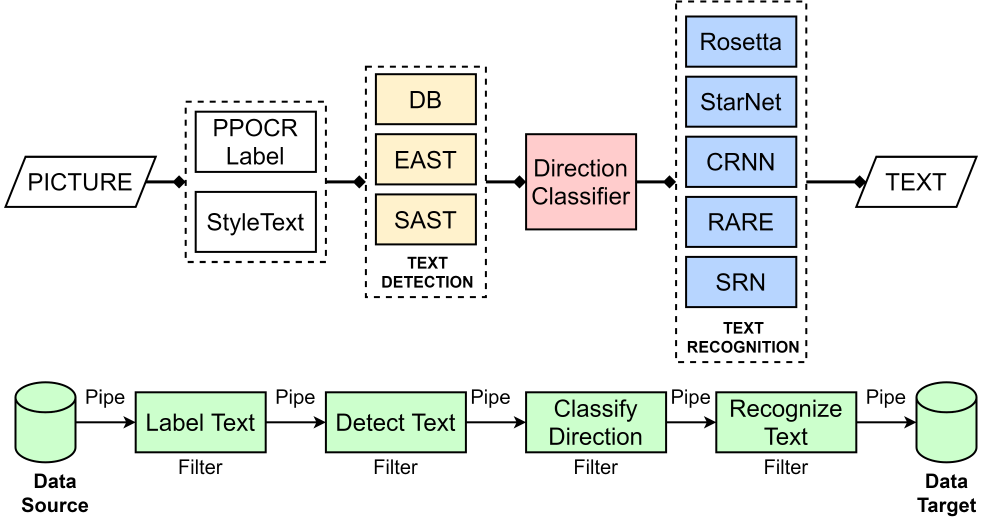
A high-level architecture of PaddleOCR is given below.
Document Pre-Processing
In order to get accurate results from the OCR, we applied the below preprocessing techniques to our input files. These techniques helped us reduce the noise and correct the orientation of the files.
Image Rotation
Some of the images in our dataset were skewed. So we checked the orientation of the image along with some keywords found at the beginning or end of the invoices and then rotated the image appropriately using OpenCV.
Shadow Removal
Shadows caused by occluded light sources can make detection more difficult. We removed such shadows using predefined functions in the OpenCV package to help the model detect more text from the input images.
Otsu's Threshold
Images with dark backgrounds make text detection more complex. We used Otsu’s image thresholding to differentiate between foreground and background pixels and improve detection accuracy.
Image Resizing
The font size of the text in most of the files was small. In order to detect and recognize these characters, we scaled the image to the appropriate size using OpenCV's resize method.
Enhancing Image Resolution
Our dataset also contained screenshots of PDF invoices. Such low-resolution images can make the extraction process harder (see sample below).

The text and their respective bounding boxes recognized by PP-OCR are shown below.

As you can see, only a small part of the text has been detected. So we decided to upscale the quality of the images. At first, we tried a deep learning-based super-resolution model provided by the Image Super Resolution (ISR ) library in Python. While the model improved image quality, image extraction took time. On a GPU machine, it took 13 seconds, and on a CPU machine, 240 seconds.
To avoid GPU dependency and improve extraction speed, we decided to go with OpenCV's Fast Super-Resolution Convolutional Neural Network (FSRCNN) algorithm. FSRCNN is based on a shallow network design that is faster and more accurate than its predecessors in reproducing images. After using FSRCNN, the inference time on CPU machines dropped to 6 seconds.
The below image shows the detected text and their respective bounding boxes recognized by PP-OCR after introducing a super-resolution model. Image resolution improved, making text detection easier.
Model Optimization
To improve the speed of the OCR model, we made it as light as possible using quantization. In simple terms, quantization is the process of rounding off the weights of the model to lower precision values so that it will consume less memory. Besides the performance benefit, quantized neural networks also increase power efficiency through reduced memory access costs and increased compute efficiency. For the native PaddleOCR model, the average time was around 6 seconds. After quantization, it further dropped to 4 seconds.
Reconstruction of Input File
From PaddleOCR, we got the detected words and their location as bounding boxes. We arranged the words extracted by the OCR based on their X and Y positions and reconstructed the input file as a PDF file. This PDF file was read using pdftotext python library to help group nearby text blocks and reduce the skewness of lines.

With these steps, we were ready for information extraction, which you can read about in Part 2.
Stay tuned!

