


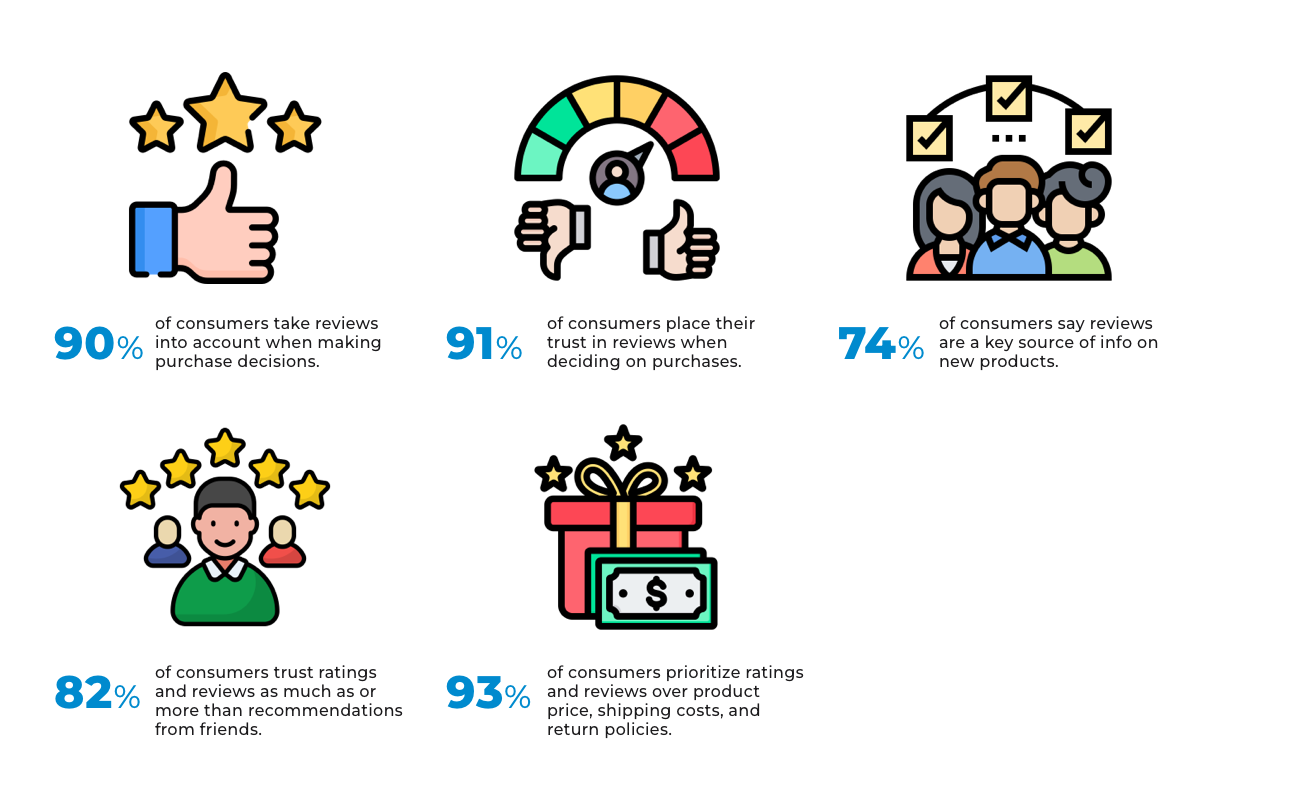
Reviews have become a trusted source of guidance for customers today.
Reviews also influence shopping decisions. A recent survey of more than 6000 U.S. consumers shows that nine out of ten customers consider user feedback while making a purchase. Reviews are also the primary means through which over 74% of customers discover new products.
In short, the collective wisdom of the crowd wields more influence over purchase decisions than any marketing campaign today.
But reviews are open to misuse. Fake, abusive, and irrelevant comments can make their way into user reviews and erode trust in a platform's services and products.
On the other hand, when users encounter respectful and meaningful feedback, it helps them assess the products or services better. This, in turn, leads to higher user satisfaction and a higher likelihood of making a purchase.
3 Review Components That Erode User Trust
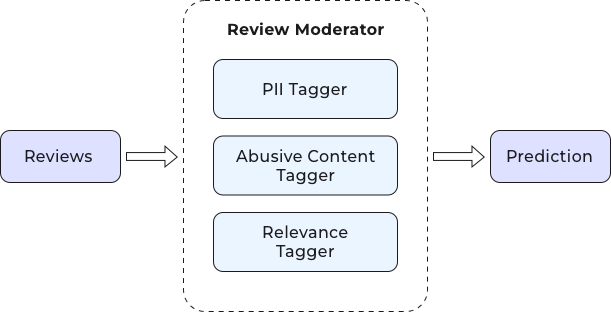
In this post, we will discuss three important aspects of review moderation that could impact a platform's credibility:
- Accidental disclosure of personally identifiable information (PII): Accidental disclosure of PII can compromise the privacy and security of individuals and lead to compliance violations in many countries. Worse, PII, when exposed, can be exploited by malicious actors for fraudulent activities.
- Abusive or inappropriate content: This can take the form of hate speech, personal attacks, or inappropriate language that can cause emotional harm to users. Such content can erode users' sense of safety and trust and ultimately lead to loss of engagement.
- Irrelevant content or spam: Irrelevant content diminishes the overall user experience. A flood of spam undermines the trustworthiness of the platform as users become skeptical about the authenticity of reviews and recommendations.
A globalized business model presents an additional challenge: linguistic diversity. As platforms cater to a global audience, reviews may be submitted in different languages. However, this should not be a barrier to content moderation.
Solution: AI-Powered Review Moderator
With the rapid progress of AI, innovative solutions are available to overcome the challenges of content moderation. NLP algorithms play a crucial role in content moderation by identifying the intended meaning and emotions underlying a text. Text classification techniques help assign categories or sentiment labels based on the content, allowing for efficient categorization and analysis. Entity recognition is another powerful AI technique, which identifies and extracts names, locations, and personal information. It plays a crucial role in enhancing privacy protection and ensuring compliance with data regulations.
Detection of Personally Identifiable Information
To create a PII moderation system, we started off by identifying important personal information. This includes Name, Address, Phone Number, Email, and Credit Card Number.
For each PII data type, we adopted a different identification approach:
- Data with fixed format: To identify phone numbers, email addresses, and credit card numbers in reviews, we utilized CommonRegex, a Python library that offers a user-friendly interface with common regular expressions. Since this data is typically written in a similar format across languages, the same could be applied everywhere.
- Names and addresses: To identify mentions of names and addresses in reviews, we used named entity recognition (NER). NER involves identifying and categorizing entities in text into predefined categories. To implement NER, we leveraged SpaCy, an open-source Python library. Depending on the language of the review, the respective SpaCy language model was used.
Detection of Abusive Content
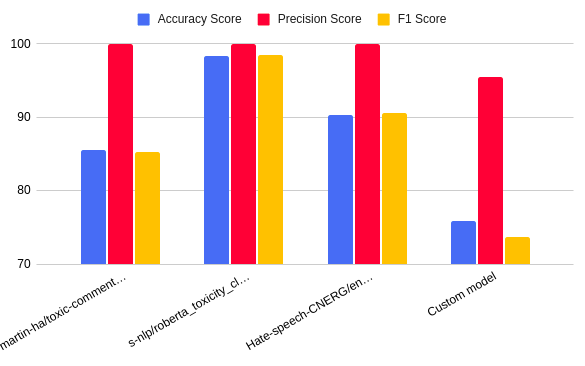
Our goal here was to detect instances of hate speech, sexism, racism, and other forms of toxic language. For this, we tried both pre-trained models as well as our own custom-trained model.
The pre-trained models were toxic-comment-model, roberta_toxicity_classifier, and english-abusive-MuRIL, which are available from the Hugging Face model repository.
We created a custom text classification model using Spacy's SpanCategorizer. This component in the Spacy library is designed for span classification tasks, where predefined labels or categories are assigned to specific segments of text within a larger document. By leveraging this, we trained and fine-tuned our model using a dataset of 2000 reviews.
Instead of providing a binary indication of whether a review is abusive or not, our custom-trained model focuses on identifying and highlighting inappropriate terms within the review, offering a more nuanced analysis of offensive content.
The chart below illustrates the difference in the performance of the pre-trained and custom-trained models.
Measuring Relevance
Here our objective was to develop a text classifier capable of analyzing customer reviews and predicting their relevance. Relevance is context-dependent, which requires the classifier to analyze the entire review in order to make accurate predictions.
We decided to evaluate relevance using two promising deep learning algorithms: Long Short Term Memory (LSTM) and BERT transformer.
LSTM-Based Classifier
To build a relevance classifier model, we used a labeled dataset consisting of 1455 English reviews. To train and evaluate the model, we partitioned the dataset, allocating 80% for training and 20% for testing.
To vectorize the reviews, we employed LASER, a multilingual word embedding technique. This enabled us to transform the text data into numerical vectors suitable for training our model. Using these vectorized reviews, we trained an LSTM model. The trained model was then evaluated using the test dataset.

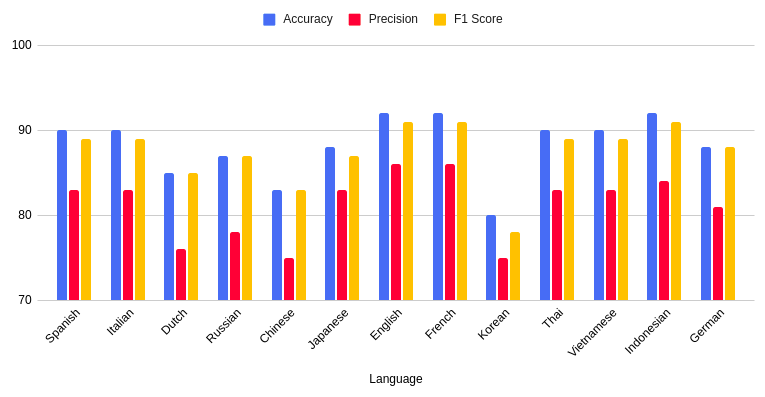
To assess its generalization capabilities and extend its usage to non-English reviews, we further tested the model on non-English datasets.
Despite being trained on a limited dataset, the model achieved accuracy levels exceeding 90% for English, French, and Indonesian. For most other languages, the accuracy ranged between 80-90%. The accuracy, precision, and F1 score of this model can be improved by using a larger dataset.
BERT-Based Classifier
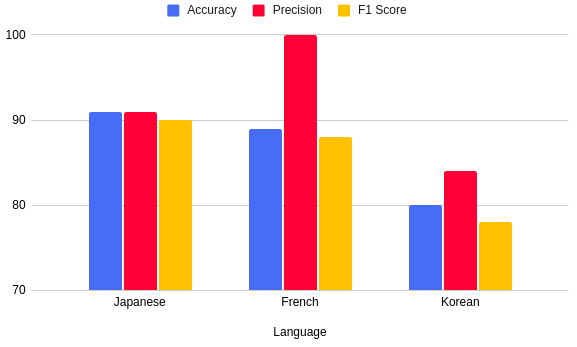
The BERT language model can differentiate the same words used in different contexts. To utilize BERT for our task, we initially trained the model using the training dataset. We then evaluated the performance of the trained BERT model on the test dataset. We used Google's translation Python package to translate the non-English reviews into English. These translated reviews were then passed as input to the BERT model.

By utilizing Google's translation services to translate non-English languages to English, we achieved an accuracy close to 100% for French. For Japanese, we achieved accuracy above 90%, but the accuracy was lower for Korean. To further improve the model's performance, we can consider using translation services specific to each language.
Conclusion
The capabilities of advanced AI models to perform tasks such as spam detection, offensive language detection, and identification of named entities can be leveraged to build a sophisticated user review moderation system. By applying predefined rules and algorithms, the system can categorize and filter reviews.
To make the system more accurate and adaptable, a feedback loop can be included, where human moderators review and validate the system’s decisions. This ongoing process helps refine and improve the model’s performance, ensuring it aligns with the specific requirements and policies of the business.
Thus, by improving the quality of reviews through moderation, trust and the overall user experience can be improved. Increased trust means more users will engage with the platform, make more purchases, or seek more services.
