

The ability to track moving objects across multiple camera feeds is of immense value to us. From baggage monitoring in busy airports to product tracking in large retail stores, there is a strong case for applications of this nature. In principle, this is simple. The tracking system first detects objects entering a camera's view and re-identifies them as they appear in different cameras. In practice, this remains an intriguing computer vision problem.
Challenges in Multi-Camera Object Tracking
Methodologies for tracking objects from a single camera feed are well-established. The most common ones use a combination of detection algorithms and tracking mechanisms like DeepSORT. Extending this capability to multi-camera scenarios is not as simple.
The same object can look different in different cameras due to changes in illumination, prolonged occlusion, and shadows. Objects may bend, dent, or otherwise change shape during transit. They may also be captured from different angles depending on the position of the cameras. These variations can make consistent re-identification across cameras difficult.
Leveraging Deep Learning-Based Custom Association Model
Successful multi-camera tracking demands a robust mechanism for re-identifying objects across separate camera perspectives. To address this, we decided to use a combination of object detection, DeepSORT tracking algorithm, and a custom object association model. The choice of a deep learning approach was inspired by how we humans associate or re-identify objects from different points of view. To test the usability of this approach, we tracked three cartons across three non-overlapping cameras.
Components of Our Study
YOLO Object Detection
YOLO (You Only Look Once) is a real-time object detection system that can process entire frames in a single pass and identify the location and class of multiple objects. In our case, YOLO was trained to detect multiple cartons in image frames. We went with YOLOv7 as it was the latest version available at the time of our study.
DeepSORT for Object Tracking
Once objects are detected, the next step is ensuring they are tracked across multiple frames from a single camera feed. They should be trackable even if they change appearance, move at varying speeds, become occluded by other objects, or interact in complex ways. To address this challenge, we employed DeepSORT, a deep learning-based object tracking algorithm.
DeepSORT is good at associating objects across frames, which it does by assigning them consistent identities over time. It leverages a combination of appearance and motion information to accurately match detected objects, effectively handling occlusions and interactions. It uses appearance features (regions of interest or ROI) extracted by YOLOv7 as inputs. For motion information, DeepSORT uses the popular Kalman filter to estimate the state of the cartons, which includes their position, velocity, and acceleration. The Kalman filter predicts the state of each carton in the current frame based on its last known state.
Custom Association Model
While DeepSORT excels in intra-camera tracking, cross-camera association presents a unique challenge. To address this, we developed a custom association model trained on images from four distinct cartons with unique labels. We chose four as an arbitrary number for the experiment. Any number of distinct cartons can be used to train the model.
Our custom association model leverages a Siamese network trained using triplet loss with Xception network as the base model. This approach helps to intelligently link cartons across different camera views, ensuring tracking continuity and accuracy. How this mechanism works is shown in Figure 1.
Visual features (known as embeddings) corresponding to the cartons are extracted from the association model, which is a one-dimensional vector of length 2048. The embeddings for all the cartons are compared against one another using cosine distance. If the cosine distance is less than a threshold value, it indicates that the embeddings belong to the same carton. Conversely, if the distance is greater than the threshold, it means the cartons are different.
Embeddings Before and After Training
For robust association, embeddings from the same cartons should be similar while those from different cartons should be different. Training the association model with the triplet loss function achieves this.
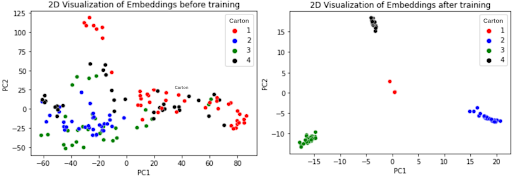
Figure 2 is a visualization of embeddings from the association model before and after training. These embeddings—originally of shape 1 X 2048—are decomposed into a 2-dimensional space using principal component analysis (PCA) for visualization. Each color represents a different carton (as shown in the legend).
The plot on the left depicts the initial embedding positions without distinct clusters. This aligns with our expectations as the model hasn't learned to differentiate between the cartons yet. The plot on the right displays the same data points after training. Clustering is evident here, which indicates the model has successfully learned to differentiate different cartons.
Multi-Camera Tracking in Action
The real-time system continuously analyzes video feeds from all cameras concurrently. Each frame is processed by YOLOv7 to detect the cartons. Upon detecting a carton, the Deep SORT algorithm assigns a unique ID to it. If a carton has already been seen by another camera, its newly assigned ID is replaced with its existing ID stored in a database. This ensures consistent tracking. If the carton is new, its unique ID is retained.
To verify the above, the detected carton's ROI is passed to the custom association model to extract its embedding (referred to as query embedding). This query embedding is compared to embeddings of all carton boxes previously detected by any camera, stored in a database. If the cosine distance is above the threshold, the ID of the detected carton remains unchanged. This implies that the carton is new and has not been identified by any of the other cameras. The embedding and the carton’s ID are added to the database for future comparisons. If it is below the threshold, the detected carton's ID is updated to match the ID of the previously seen carton.
Conclusion
With the multi-camera tracking algorithm we developed using YOLO, DeepSORT, and custom object association model, we were able to accurately track cartons moving between multiple cameras in real time. The custom association model was able to cross-associate objects, overcoming challenges like occlusion, varying lighting conditions, and complex interactions between cartons. This proof of concept demonstrates the potential of our algorithm in tracking non-identical objects across camera feeds.
There is, however, room for improvement, particularly in scenarios where visually similar objects with no unique features have to be tracked. Incorporating additional features such as the direction of motion and spatial coordinates can be valuable in such a case. This extension would transform the association model into a multimodal model that leverages both image ROI and a single-dimensional vector embedding spatial and directional information. This approach promises to effectively address the complexities of multi-camera identical object tracking.
Do you have a unique computer vision challenge to solve? Write to us!
