


Vision language models represent a new generation of deep learning frameworks capable of processing both images and text as input and producing either as outputs. Though still relatively new, businesses are beginning to recognize the potential of these models and are gradually integrating them into applications.
Vision language models can be used to query images, classify objects, detect items, and generate descriptive text, making them versatile tools across domains. A key advantage is that they can deployed for tasks where labeled data is scarce and custom model training is not feasible.
Open-source vision language models are available for those seeking affordable alternatives to commerical models that come with licensing restrictions. Although they may not be on par in terms of accuracy and performance, they can still effectively meet many business needs.
In this blog post, we'll explore the performance of some open-source multimodal models in two security-related contexts. We will also compare the precision and recall of these models against a shallow CNN custom model developed specifically for these tasks. The goal is to determine whether a generic, open-source multimodal model can outperform a task-specific model trained using in-house data and resources.
Key Features of Vision Language Models
- Zero-Shot Learning: Vision language models are capable of zero-shot learning, which allows them to understand and respond to tasks they were not explicitly trained on. This makes them useful in a wide range of applications.
- Multimodal Integration: Vision language models excel at integrating visual and textual information, enabling them to understand context and nuance. This integration is crucial for tasks like image captioning, visual question answering, and document understanding.
- Spatial Awareness: Some vision language models can capture spatial properties within images. This means they can generate output like bounding boxes or segmentation masks to detect or segment particular subjects in images. They can also localize different entities and answer questions about their relative or absolute positions.
Test Case
Our test case involved the monitoring of a high-security IDF closet. There were two requirements:
- Door Obstruction Monitoring: The closet being monitored must be unobstructed at all times. If a person or object blocks the doorway for too long, an alert must be triggered.
- Power Backup Monitoring: A power backup machine in the closet is equipped with an LED indicator. If the LED changes from red to any other color, an alert should be sent.
Analyzing live camera feeds, the system should be able to answer the following queries accurately:
- Is any object or person blocking the doorway?
- What is the color of the LED light on the power backup machine?
Models and Results
We analyzed the performance of four models on a set of 90 images. The results and a detailed code implementation using a T4 GPU on Google Colab are presented below.
1. LLaVa
LLaVA is a multimodal LLM designed to excel in chat and instruction-based interactions. Built on the transformer architecture, LLaVA is capable of processing both text and visual information. It extends the functionalities of traditional LLMs by incorporating visual inputs, allowing users to engage in conversations that seamlessly blend text and images. It is widely regarded as an open-source counterpart to OpenAI’s GPT-4 model, offering similar capabilities in interactingwith visual data.
Implementation
import requests
from PIL import Image
import torch
from transformers import BitsAndBytesConfig
from transformers import pipeline
image_path = "image.png"
image = Image.open(image_path)
quantization_config=BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_compute_dtype=torch.float16)
model_id = "llava-hf/llava-1.5-7b-hf"
pipe = pipeline("image-to-text", model=model_id, model_kwargs={"quantization_config": quantization_config})
max_new_tokens = 200
prompt = "USER: <image>\nCheck if there is any object blocking the door way in the image\nASSISTANT:" #add your query here
outputs = pipe(image, prompt=prompt, generate_kwargs={"max_new_tokens": 200})
print(outputs[0]["generated_text"])
Results

2. MiniCPM-V 2.0
The MiniCPM series of models is a resource-efficient alternative to LLMs. MiniCPM-V 2.0 is built on MiniCPM 2.4B and SigLip-400M, totaling 2.8 billion parameters. Despite its relatively smaller size, it demonstrates better multimodal understanding capabilities, achieving state-of-the-art performance on OCRBench among open-source models and matching Gemini Pro in scene-text understanding.
MiniCPM-V 2.0 excels in high-resolution image processing (up to 1.8 million pixels), supports flexible aspect ratios, and offers strong support in English and Chinese. Moreover, it is designed for efficient deployment on a wide range of devices, from personal computers to mobile phones, making it highly accessible. Importantly, MiniCPM-V 2.0 demonstrates trustworthy behavior, being aligned via multimodal reinforcement learning from human feedback (RLHF), effectively preventing hallucinations and achieving reliability comparable to GPT-4V.
Implementation
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2', trust_remote_code=True, torch_dtype=torch.bfloat16)
model = model.to(device='cuda', dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2', trust_remote_code=True)
model.eval()
image_path = "image.png"
image = Image.open(image_path).convert('RGB')
question = 'What is the color of LED light in the device?' #add your query here
msgs = [{'role': 'user', 'content': question}]
res, context, _ = model.chat(
image=image,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True,
temperature=0.7
)
print(res)
Results

3. KOSMOS-2
KOSMOS-2, developed by Microsoft, is a transformer-based causal language model trained on the next-word prediction task using GRIT, a vast dataset of grounded image-text pairs. In this dataset, the spatial coordinates of bounding boxes are transformed into a sequence of location tokens, which are then appended to their corresponding entity text spans. The data format used for training is similar to hyperlinks, that is, object regions in an image will be linked to their text spans or words in the caption. This approach reduces hallucination.
Implementation
from PIL import Image
import requests
from transformers import AutoProcessor, Kosmos2ForConditionalGeneration
from google.colab import drive
drive.mount('/content/drive')
model = Kosmos2ForConditionalGeneration.from_pretrained("microsoft/kosmos-2-patch14-224")
processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
image_path = "image.png"
image = Image.open(image_path)
prompt = "<grounding> An image of a device with an LED light. What is the color of the LED light?" #add your query here
inputs = processor(text=prompt, images=image, return_tensors="pt")
generated_ids = model.generate(
pixel_values=inputs["pixel_values"],
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
image_embeds=None,
image_embeds_position_mask=inputs["image_embeds_position_mask"],
use_cache=True,
max_new_tokens=64,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
processed_text = processor.post_process_generation(generated_text, cleanup_and_extract=False)
processed_text
res, entities = processor.post_process_generation(generated_text)
print(res)
Results

4. Moondream2
Moondream2 is a compact vision-language model designed to operate efficiently on low-resource devices. With 1.86 billion parameters, it is initialized with weights from SigLIP and Phi-1.5. Moondream2 excels in answering questions about images, generating captions, and performing various other vision language tasks, all while running smoothly on edge devices with minimal memory.
Implementation
pip install transformers einops from transformers import AutoModelForCausalLM, AutoTokenizer from PIL import Image import os model_id = "vikhyatk/moondream2" revision = "2024-05-20" model = AutoModelForCausalLM.from_pretrained( model_id, trust_remote_code=True, revision=revision ) tokenizer = AutoTokenizer.from_pretrained(model_id, revision=revision) query = "What is the color of the LED light in the image ?" #add your query here image_path = "image.png" image = Image.open(image_path) enc_image = model.encode_image(image) print(img) print(model.answer_question(enc_image, query, tokenizer))
Results

Model Performance Compared to CNN Model
The models produced reliable, contextually appropriate answers, demonstrating an understanding of the queries and providing logical responses. However, when compared to our custom CNN model, the vision-language models underperformed (see table below).
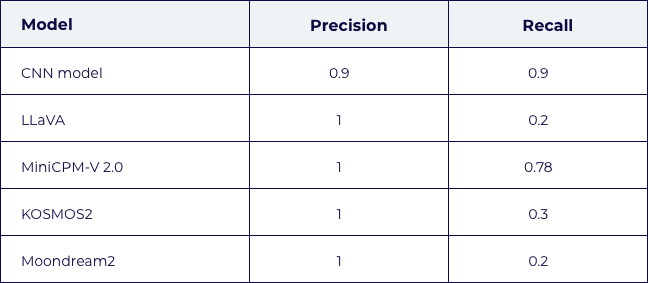
While all models showed high precision—indicating that they handle true positive scenarios well (correctly identifying a red LED light or a blocked door)—most, except for MiniCPM-V 2.0, exhibited low recall. This means that the models could misclassify an unblocked doorway as blocked or a differently colored LED as red. In contrast, our custom CNN model showed high precision and recall, outperforming the vision-language models.
Most failures with the vision-language models occurred because they struggled to accurately infer the depth and position of objects. From this experiment, it is clear that these models are still in their early stages of development but hold great potential. With improvements in architecture and more extensive training data, these models are likely to be more accurate in the future.
