


Large Language Models (LLMs) have revolutionized the field of natural language processing (NLP) with their impressive ability to understand context and generate high-quality responses. However, their large number of parameters comes at a cost: high computational demand and longer inference times.
To address these challenges, researchers have been exploring Small Language Models (SLMs). Unlike LLMs, which rely on a large number of "learned" features, SLMs prioritize a smaller, more targeted set of parameters. This enables SLMs to overcome key limitations of LLMs and improve efficiency in specialized tasks.
Pioneering models in the SLM category include GPT-2 Small, Phi-3-mini, and Gemma 2. GPT-2 Small is a downsized version of GPT-2, while Phi-3-mini, from Microsoft’s Phi-3 family, is an SLM designed for language processing, reasoning, and coding tasks. Gemma 2, part of Google’s open Gemma family, is a 2-billion-parameter model based on the Google Gemini LLM.
What Makes Small Language Models Tick?
Small Language Models leverage techniques like distillation and pruning to maintain key performance characteristics despite the size reduction. These two techniques enable SLMs to retain essential knowledge and capabilities while reducing their computational requirements.
Knowledge distillation involves transferring knowledge from a larger, pre-trained model to a smaller model, allowing the smaller model to mimic the behavior of the larger model. Pruning, on the other hand, involves removing redundant or unnecessary parameters from the model and streamlining its architecture.
The base SLM models have learned the fundamental language patterns. To optimize their performance for specific use cases they are fine-tuned using domain-specific data or combined with specialized architectural patterns.
Customizing SLMs For Domain-Specific Tasks
Today, several companies offer open-source SLMs with flexible licensing options. Some popular models include Phi-3, Llama 3, Gemma, Mixtral 8x7B, and OpenELM. SLMs are customized using techniques such as:
Retrieval-Augmented Generation (RAG): Complements SLMs by providing access to external knowledge, enhancing relevance and accuracy.
Domain-Adaptive Pretraining (DAPT): Helps SLMs develop focused expertise with ample domain-specific data.
Multi-Task Learning (MTL): Trains SLMs to perform multiple related tasks within a domain, helping the model recognize beneficial patterns.
Self-Supervised Learning (SSL): SSL with Domain-Specific Objectives enables the model to acquire domain-specific insights independently.
Reinforcement Learning from Human Feedback (RLHF): Refines the SLM's responses using human feedback, enhancing quality for specific applications.
Prompt Engineering: Optimizes the input prompts given to the SLM without modifying model parameters, improving its response to specific queries.
Fine-tuning: Includes training the model on a smaller, domain-specific dataset to refine its understanding and generate more accurate responses.
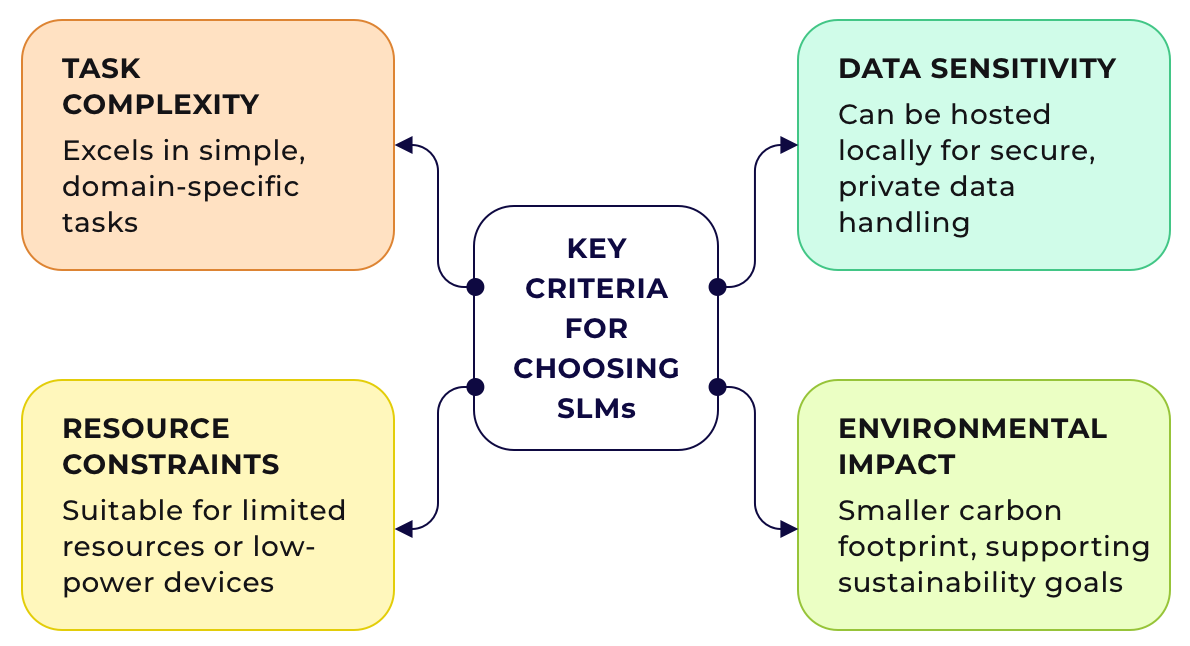
Key Criteria for Choosing SLMs for Your Business
Before integrating SLMs into your business workflow, consider whether they meet your project's unique needs. To determine if SLMs are the right fit, consider these criteria:
Task Complexity: SLMs are suitable for straightforward tasks like customer support assistants. However, an LLM might be necessary for complex tasks that require nuance and context, such as drafting contracts or conducting sentiment analysis.
Resource Constraints: SLMs are better suited for budget-conscious projects or deployment on devices with limited processing power, such as voice assistants on IoT devices, due to their lower resource requirements.
Data Sensitivity: If privacy and data security are paramount, consider SLMs that can be hosted locally and trained on proprietary data. This is particularly relevant for use cases such as fraud detection, medical diagnosis assistance, document classifiers, or inventory management systems.
Environmental Impact: For organizations with sustainability goals, SLMs offer a smaller carbon footprint due to their reduced computational requirements.
Performance and Limitations
As technology advances, the performance gap between newer LLMs is narrowing. This may indicate that LLMs are approaching their peak potential. Meanwhile, innovative SLMs are emerging, with some fine-tuned models like Orca Math and DistilBERT demonstrating performance comparable to their LLM counterparts.
When fine-tuned with quality domain-specific data, SLMs demonstrate competitive performance in high-precision tasks. In industries like healthcare or finance, where terminology is specific and narrow in scope, SLMs can deliver responses that are as accurate and contextually appropriate as those from larger models.
By narrowing their focus, SLMs simplify the fine-tuning process. Their smaller size enables local hosting, which enhances privacy and security. As SLMs are often trained on proprietary datasets and run within controlled environments, they support easier compliance with data privacy laws.
While SLMs can perform competitively within specific domains, they do have limitations. Research shows that SLMs excel in high-precision tasks within their specialization, but for broader applications, such as multilingual support or handling ambiguous language, LLMs may outperform SLMs.
Ultimately, the choice between an LLM and an SLM depends on the specific problem you're trying to solve. For now, leverage SLMs for efficient, specialized task execution and reserve LLMs for applications requiring comprehensive language capabilities.
