


Scaling online coding assessment platforms is challenging because of the unpredictable and dynamic nature of the load. Thousands of candidates may log in simultaneously when an exam starts, causing sudden spikes that test the limits of traditional auto-scaling methods.
Our Site Reliability Engineering (SRE) team recently tackled this challenge head-on, working closely with the development team to build a custom scaling solution that not only ensured system reliability and performance but also introduced significant cost efficiencies.
While SRE is often discussed in terms of improving system reliability through well-defined SLAs, SLOs, and SLIs, our experience shows that the role of SRE extends far beyond those principles.
Problem Overview
The coding assessment platform Evalgator offers two test modes: (1) Slot-based Assessments, where candidates take the test in predefined time slots. (2) Open Slot Assessments, where candidates are offered a flexible test window (For example, within a 24-hour or a 2-week period). Both these modes have their own load management challenges.
Sudden Load Spikes
For Slot-based Assessments, the load is not gradual but a sharp spike, with thousands of users logging in at the same time (common in campus recruitment scenarios). For example, at 9:58 AM, the system might have no active users, but by 10:00 AM, tens of thousands of candidates could begin the test simultaneously.
Out-of-the-box auto-scaling is not suitable for such sudden spikes. By the time the scaling action is triggered based on CPU or memory load, the user experience would have already degraded due to lag or failed sessions. Event-driven serverless scaling is not feasible due to the nature of the compute and setup required.
The operations team used to handle this challenge by manually scaling up infrastructure based on anticipated load. But they ran the risk of over-provisioning, which increased cloud costs, or under-provisioning, which led to poor user experience.
Unpredictable Traffic Patterns
The Open Slot Assessment feature introduced even bigger challenges. Provisioning for peak load for the entire window was expensive and inefficient because traffic was highly unpredictable. Users could start the test at any time during the open period, which could span days or even weeks.
Load spikes could occur at any time during this window, making it difficult to predict demand accurately. Unlike transactional systems where constant requests define load, coding platforms involve long periods of inactivity while candidates write code, followed by sudden computationally heavy requests when the code is executed.
The compute requirements also varied significantly. Factors like the number of test cases, the frequency of code execution, and the programming language used (Python, Java, C++ each have different runtime demands) created highly inconsistent load patterns.
Multi-Step Approach by SRE Team
Our SRE team devised a strategy that balanced system reliability with cost efficiency.
Step 1: Intelligent Forecasting and Alerting for Slot-Based Assessments
The first step was to reduce the manual burden on the operations team.
- Custom Dashboard: The team built a real-time dashboard that forecasts anticipated load based on historical patterns and scheduled assessments.
- Automated Alerts: Alerts were integrated into Microsoft Teams to notify the operations team about upcoming spikes and recommended scaling actions.
Scaling could have been automated at this point, but the team decided to address it along with the Open Slot challenge.
Step 2: Building a Custom Auto-Scaler for Open Slot Assessments
Since traditional auto-scaling could not handle the unpredictable load of Open Slot Assessments, the team designed a custom auto-scaler from scratch.
Here’s how it works:
1. Event-Driven Scaling Based on Assessment Start
- Scaling is not based on CPU/memory usage but at the actual start of the assessment by a candidate.
- When a candidate starts an assessment, the system:
- Checks the current number of active candidates.
- Verifies the available compute capacity.
- Cross-checks for any upcoming slot-based assessments within the next 15 minutes.
If there is insufficient capacity, the system:
- Sends a trigger to spin up additional compute nodes.
- Prepares additional "candidate seats" to reduce wait time for subsequent candidates.
2. Queue-Based Admission Control
- If multiple candidates start the test simultaneously and the infrastructure is at capacity, candidates are temporarily queued.
- The system allows them to start the test once compute resources are available.
- A real-time feedback mechanism notifies the candidate about the wait time.
3. Dynamic Load Distribution
The system dynamically distributes candidates across multiple compute clusters based on:
- Programming language selected (since some languages have higher CPU demands).
- Number of active test cases.
- Historical performance of the cluster.
4. Efficient Resource Cleanup
- Candidates are tracked using a heartbeat mechanism, a lightweight signal sent at regular intervals to indicate they are still active.
- If a candidate becomes inactive (abandons assessment), the system automatically deallocates resources after a timeout.
- On submission of the assessment, resources are immediately released.
- Completed sessions are moved to low-cost storage for reporting and analysis.
5. Smart Scaling to Optimize Cost and Performance
- Instead of scaling one node at a time, the system scales based on a cluster threshold.
- Scaling is done to maintain a buffer, ensuring at least 5–10% extra capacity so that the next few candidates don't experience delays.
- If the buffer is crossed, a new node is spun up.
- If the buffer remains underutilized for 15 minutes, the system automatically scales down.
6. Horizontal and Vertical Scaling Combination
- The system uses horizontal scaling (adding more nodes) for high parallel demand.
- For certain types of coding languages and test cases, vertical scaling (increasing CPU and memory within a node) is triggered to handle computational spikes more efficiently.
Custom Auto-Scaler Architecture and Key Components
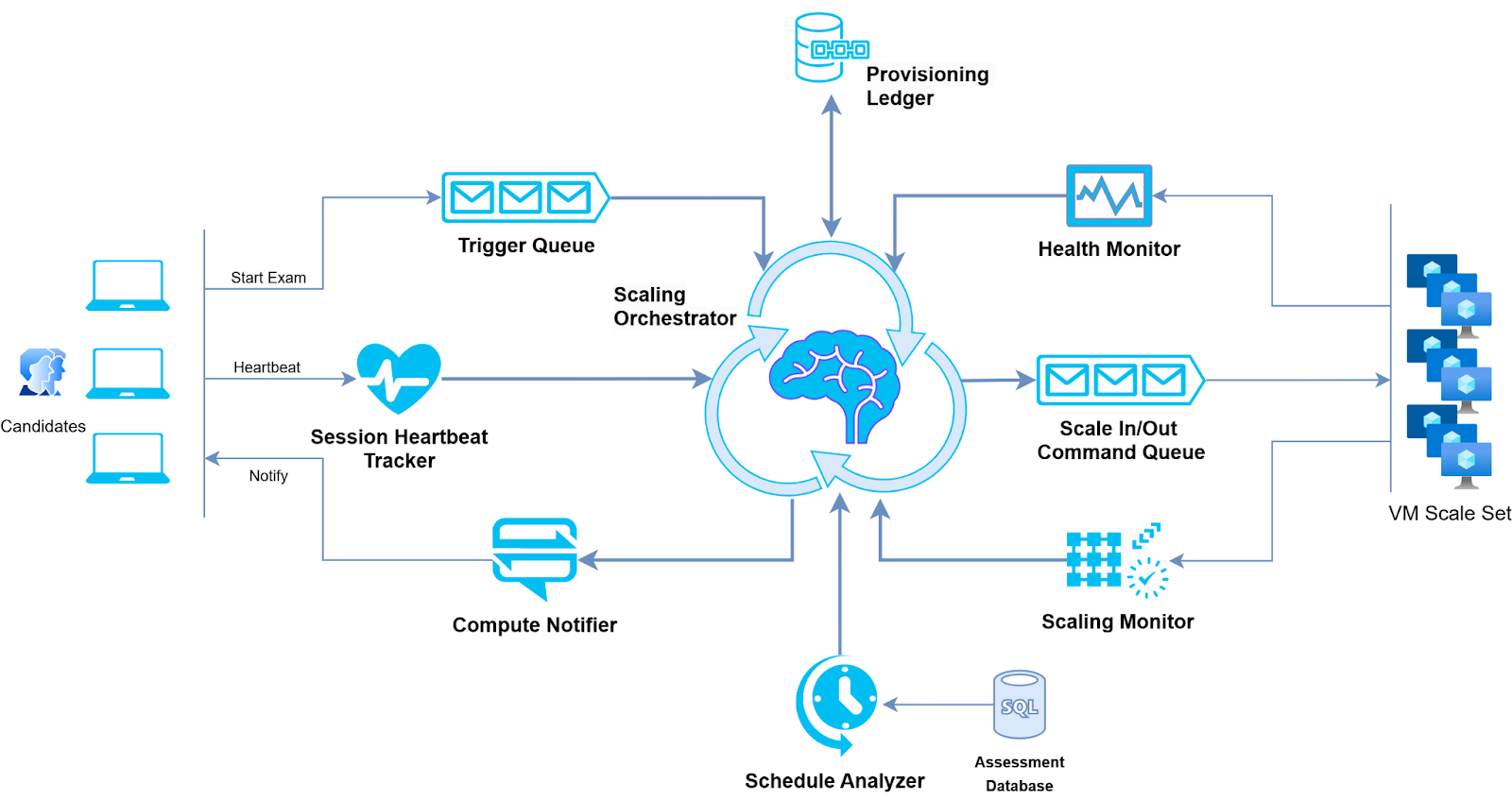
Scaling Orchestrator: Coordinates scaling decisions and manages resource allocation.
Compute Notifier: Sends real-time notifications about compute availability and provisioning status.
Health Monitor: Continuously checks the health of existing compute resources and signals the Scaling Orchestrator to terminate unhealthy instances.
Schedule Analyzer: Monitors upcoming exams and provides forecast data to the Scaling Orchestrator.
Provisioning Ledger: Logs candidate-to-compute mapping details and tracks provisioning history.
Session Heartbeat Tracker: Monitors candidate session activity through heartbeat signals and signals resource release if inactivity is detected.
SRE Implementation Approach: Concept to Reality
1. Brainstorming and Design Finalization
The SRE team initiated multiple brainstorming sessions with the development team to understand the platform’s computational demands and usage patterns. Discussions focused on how to handle varying test complexity, unpredictable spikes, and resource utilization efficiency. After multiple iterations, the design was finalized with clear signals and thresholds for scaling events.
2. Signal-Driven Scaling Strategy
The SRE team defined the key signals that would trigger scale-in and scale-out events, including candidate start time, programming language execution time, real-time queue size, and heartbeat signals for session activity. The development team was responsible for implementing these signals within the platform’s core logic, ensuring that the auto-scaler could respond dynamically to real-time system load.
3. SRE-Led Development Phase
This phase was driven by SRE requirements rather than product requirements. The development team built the hooks and triggers based on the scaling architecture designed by the SRE team. Real-time logging and monitoring were integrated to capture signal flow and scaling decisions for debugging and optimization.
4. Iterative Tuning and Rollout
After the initial implementation, the SRE team monitored the system’s response to scaling events. Several tuning sessions were held to adjust the thresholds and optimize node spin-up times. The system was rolled out in phases to control risk and ensure stability during high-traffic events.
Results
- More Resilient System: Candidates faced minimal wait times even during peak usage. Large-scale recruitments ran smoothly, unmarred by crashes or slowdowns.
- Reduced Costs: Adopting dynamic resource allocation brought down compute costs by 30%.
- Faster Rollout: The custom auto-scaler eased the launch of the Open Slot Assessment feature without infrastructure overhauls and excess overhead.
- Better Developer Collaboration: The SRE team worked closely with the development team to understand the platform’s computational needs and user behavior. Their insights also helped the product team design more scalable coding challenges and better handle edge cases.
Beyond Infrastructure: SRE's Business Value
This project highlights how SRE extends beyond traditional reliability metrics like SLAs, SLOs, and SLIs. While maintaining uptime is crucial, it underscores SRE's strategic influence in shaping platform scalability, cost efficiency, and its very evolution.
By developing a custom auto-scaler, the SRE team made the platform’s Open Slot Assessment feature feasible from both cost and performance perspectives. The team’s deep involvement in FinOps was equally impactful as they helped optimize compute resources and test complexity, reducing operational costs. Their close collaboration with the dev team influenced key design decisions and feature rollout timelines, making SRE a core part of the product lifecycle. The resulting solution is nothing short of a testament to how SRE can drive both technical excellence and business value.
