


Apache Airflow has long been one of our project’s trusted tools for orchestrating data pipelines. It efficiently handles scheduled ETL jobs and reporting tasks, especially when everything operates within a single cloud environment and follows a linear workflow.
As our application evolved with multi-cloud deployments (AWS and GCP), event-driven patterns, and long-running stateful processes (like model training), Airflow's traditional strengths began to show limitations. Specifically, managing persistent workflow state across failures, orchestrating event-based interactions across cloud boundaries, and the developer overhead for implementing the necessary resilience became significant pain points. These challenges prompted us to seek alternatives.
Why Temporal?
Temporal takes a different approach to orchestration: code-first and built to handle the complexities of distributed systems. Unlike traditional orchestration tools that rely on complex configuration files or DAG definitions, Temporal allows you to define workflows directly in your application code using languages like Python, Go, Java, or TypeScript.
Here’s how Temporal solved the issues we faced with Airflow:
Code Over Configuration
With Airflow, logic is often scattered across YAML files, custom operators, and external scripts. Temporal keeps it in one place as regular code. This makes branching, retries, and error handling feel intuitive. Dynamic behavior is implemented with native control flow, rather than through complex configurations or plugins.
Built-In Resilience
Temporal automatically checkpoints the workflow state to durable storage. If a process crashes or loses network connection, it resumes from the last checkpoint without external state management. In our proof of concept, it handled simulated failures effortlessly, whereas Airflow required significant manual effort.
Simplified Retries
In Airflow, retries often require operator-level settings or external wrappers. Temporal integrates retry logic directly into the workflow. You can define backoff strategies, retry limits, and non-retryable exceptions directly in the workflow code, which makes API timeouts easier to manage.
Transparent Debugging
Debugging in Airflow meant piecing together logs from multiple sources. Temporal gives a clear execution history in its UI and CLI, where you can inspect each step, input, output, and failure reason. This reduces debugging time from hours to minutes.
Let’s take a closer look at the Temporal architecture and how its components fit together:
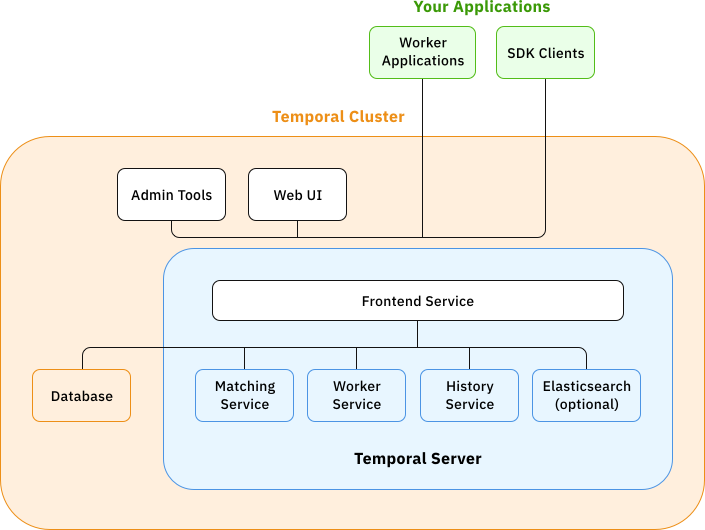
Temporal Cluster
The core platform that hosts all the server-side services required to run and manage workflows.
Temporal Server Services
These internal services power the platform’s orchestration capabilities:
- Frontend: Acts as the API gateway—receives client requests and routes them appropriately.
- Matching Service: Manages task queues and assigns tasks to the right workers.
- History Service: Maintains the complete execution history of workflows for reliability and fault tolerance.
- Worker Service: Enables communication between the server and application-level workers, coordinating activity execution.
- (Optional) Elasticsearch: Enhances workflow search capabilities within the UI and CLI.
- Database: The persistent store for workflow state, history, and metadata.
Your Applications
These are the worker processes and SDK-based clients that:
- Host your workflow and activity code
- Poll task queues for work
- Communicate with the Temporal cluster via SDKs (Go, Java, Python, etc.)
Together, these components form a robust, fault-tolerant system for orchestrating complex workflows at scale.
Implementing a Temporal Workflow in Python
In this example, we'll build a multi-cloud data pipeline with Temporal, transferring data from S3 to GCS and loading it into BigQuery. This pipeline highlights Temporal's key benefits, such as code-first orchestration, built-in resilience, and streamlined error handling.
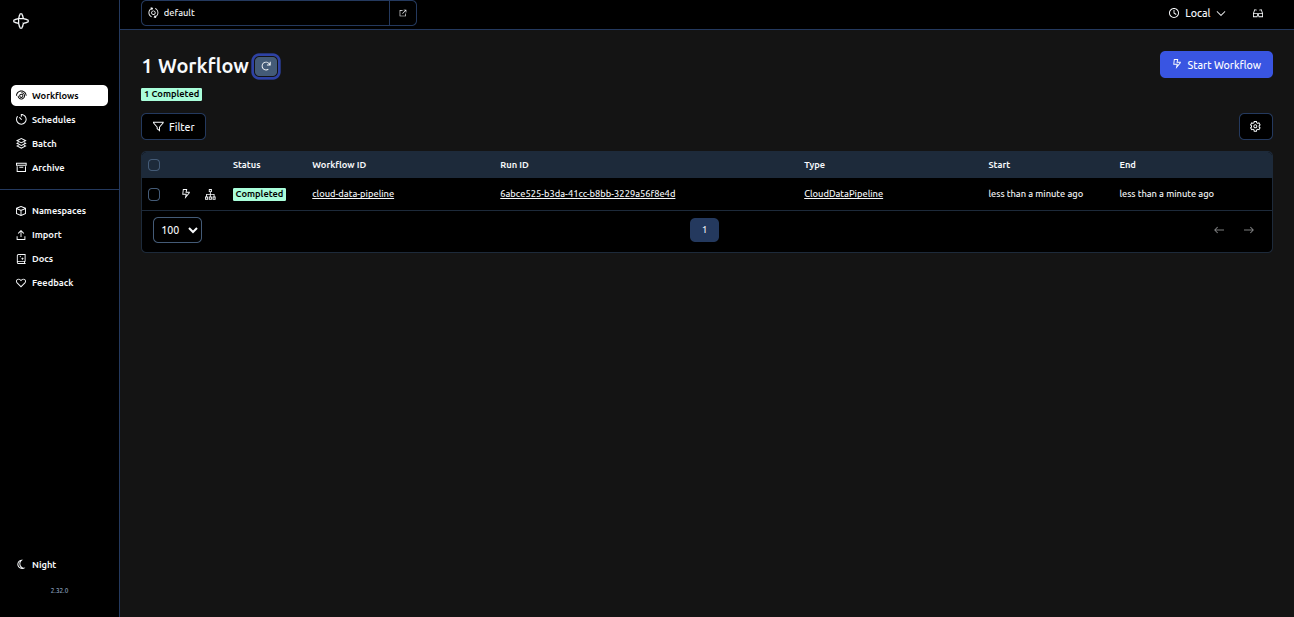
This script showcases Temporal's ability to orchestrate fault-tolerant, durable workflows entirely in Python, giving you control over retries, state, and recovery.
Step 1: Define Activities (The Work Units)
Activities perform external interactions such as API calls, database writes, or sending emails. They are typically stateless and idempotent.
Create a file named activities.py and define your activity functions there. Below is an example with mock functions that simulate the external behavior:
# activities.py
from temporalio import activity
import time
class DataTransferActivities:
@activity.defn
async def s3_download(self, source_path: str) -> str:
"""Mock S3 download operation"""
time.sleep(1) # Simulate download delay
activity.logger.info(f"Downloaded {source_path} from S3")
return f"mock-data-from-{source_path}"
@activity.defn
async def gcs_upload(self, data: str, bucket: str) -> str:
"""Mock GCS upload operation"""
time.sleep(1) # Simulate upload delay
gcs_path = f"gs://{bucket}/processed-data"
activity.logger.info(f"Uploaded to {gcs_path}")
return gcs_path
@activity.defn
async def bq_load(self, gcs_path: str, table_id: str) -> str:
"""Mock BigQuery load operation"""
time.sleep(1) # Simulate BQ load delay
activity.logger.info(f"Loaded {gcs_path} into {table_id}")
return f"{table_id}-loaded"
Step 2: Define the Workflow (The Orchestrator)
The Workflow coordinates the execution of Activities, handling their sequence, data flow, and business logic. Workflows are deterministic and resumable, meaning they can recover from failures and resume execution from the last known state.
Create a file named workflow.py and define your workflow function or class there:
# workflow.py
from datetime import timedelta
from temporalio import workflow
# Import activities through Temporal's sandbox
with workflow. unsafe.imports_passed_through():
from activities import DataTransferActivities
@workflow.defn
class CloudDataPipeline:
@workflow.run
async def run(self, s3_path: str, gcs_bucket: str, bq_table: str) -> str:
# Create activities instance
transfer = DataTransferActivities()
# Execute pipeline steps
data = await workflow.execute_activity_method(
transfer.s3_download,
s3_path,
start_to_close_timeout=timedelta(seconds=30))
gcs_location = await workflow.execute_activity_method(
transfer.gcs_upload,
args=[data, gcs_bucket], # Args as list
start_to_close_timeout=timedelta(seconds=30))
bq_result = await workflow.execute_activity_method(
transfer.bq_load,
args=[gcs_location, bq_table],
start_to_close_timeout=timedelta(seconds=30))
return f"Pipeline completed: {bq_result}"
Step 3: Create a Worker (The Executor)
The worker connects to the Temporal Server, listens on a Task Queue, and executes the registered Workflows and Activities. It serves as the execution layer of your Temporal application, processing tasks that are placed on the Task Queue.
# worker.py
import asyncio
from temporalio.client import Client
from temporalio.worker import Worker
from activities import DataTransferActivities
from workflow import CloudDataPipeline
async def main():
# Connect to Temporal server
client = await Client.connect("localhost:7233")
# Initialize worker with pipeline components
worker = Worker(
client,
task_queue="cloud-data-tasks",
workflows=[CloudDataPipeline],
activities=[DataTransferActivities().s3_download,
DataTransferActivities().gcs_upload,
DataTransferActivities().bq_load]
)
print("Starting cloud data worker...")
await worker.run()
if __name__ == "__main__":
asyncio.run(main())
Step 4: Create a Starter (To Trigger the Workflow)
This script (starter.py) connects to the Temporal server and starts the execution of the Workflow with the provided input parameters.
# starter.py
import asyncio
import sys
from temporalio.client import Client
from workflow import CloudDataPipeline
async def main():
# Connect to Temporal and start workflow
client = await Client.connect("localhost:7233")
# Get parameters from the command line
s3_path, gcs_bucket, bq_table = sys.argv[1:4]
handle = await client.start_workflow(
CloudDataPipeline.run,
args=[ s3_path, gcs_bucket, bq_table],
id="cloud-data-pipeline",
task_queue="cloud-data-tasks"
)
print(f"Pipeline completed: {await handle.result()}")
if __name__ == "__main__":
asyncio.run(main())
Step 5. Running the Pipeline
To run the pipeline:
1. Start the worker in one terminal:
python worker.py2. In another terminal, trigger the workflow using starter.py with your specific S3 source path, GCS destination bucket, and BigQuery table ID:
python starter.py s3://your-aws-bucket/input/file.csv your-gcp-bucket your-project:your_dataset.your_tableThis will initiate the workflow, which the worker will then execute.
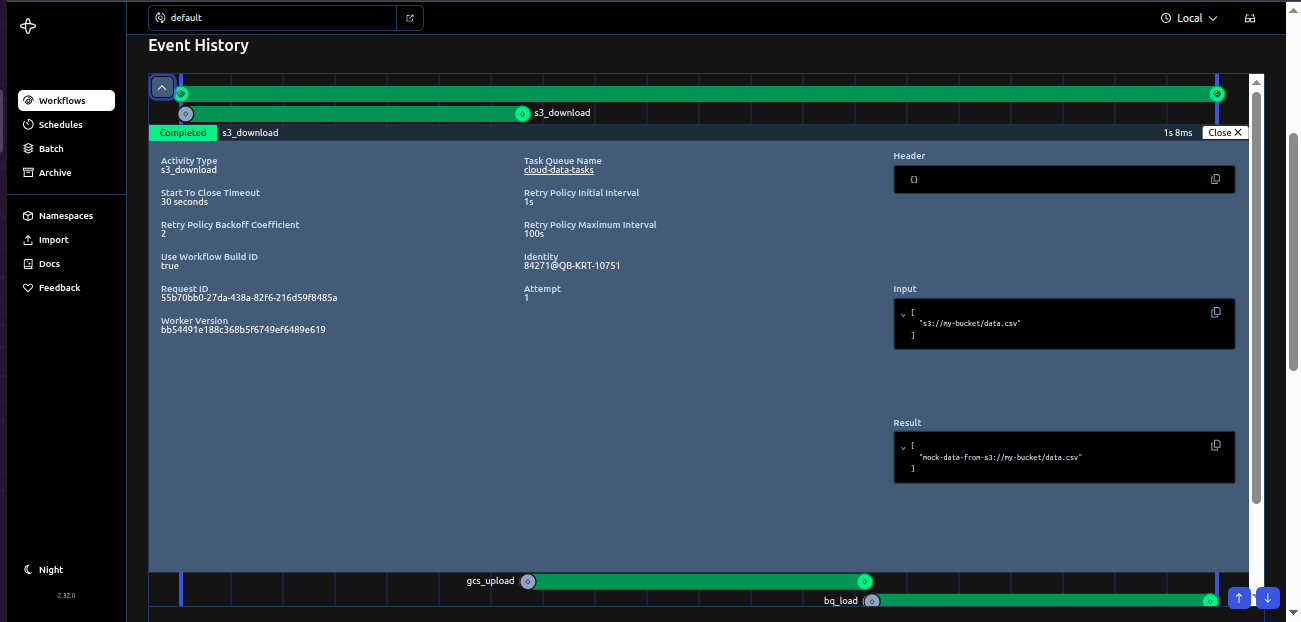
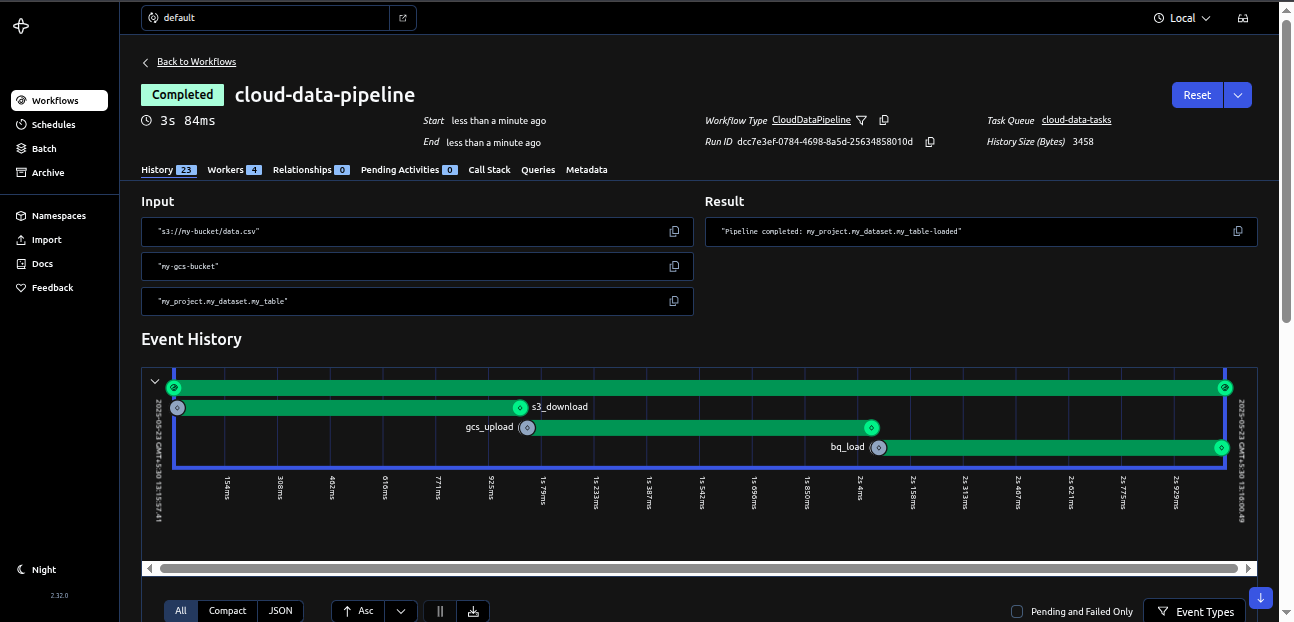
Lessons from Implementing Temporal Workflows
Temporal’s concepts, especially deterministic workflows and event sourcing, took some getting used to. Workshops and pair programming helped us ramp up. Our proof of concept with Temporal revealed a few important aspects of working with the platform:
- Tuning Retry Policies: Temporal’s built-in retries are powerful but require careful configuration, like
setting initial_intervalandbackoff_coefficientto avoid overwhelming external services. - Adapting to Temporal's Backfill Time Logic: For backfilling scheduled workflows, we needed to explicitly fetch search attributes within our workflow code to determine the logical execution time. This differed from Airflow's more direct provision of logical dates.
Choosing the Right Tool: Temporal, Airflow, or Both?
As data engineers, we’re often tasked with selecting the right tool to solve complex orchestration challenges. While Temporal proved to be a better fit for our specific needs, the choice between Temporal and Apache Airflow ultimately depends on the use case.
- Choose Temporal when you need:
- Long-running, stateful workflows that span hours or days
- Complex control flow, error handling, or external event coordination
- Reliable orchestration across microservices and cloud platforms
- Long-running, stateful workflows that span hours or days
- Choose Airflow when you’re focused on:
- Data-centric batch processing and scheduled ETL/ELT jobs
- Leveraging a rich ecosystem of prebuilt operators and integrations
- Simpler, time-based orchestration in a well-established framework
- Data-centric batch processing and scheduled ETL/ELT jobs
Many teams combine both Temporal and Airflow to play to their strengths. They rely on Airflow to orchestrate data movement and use Temporal to manage application logic that needs resilience, retries, and tight control over state and side effects. Instead of replacing one with the other, they expand their toolkit to handle real-world complexity.
Conclusion
Our exploration proved that Temporal delivers strong orchestration for modern applications. Its code-first approach, built-in state management, and fault tolerance help you build complex, distributed systems. Teams pushing the limits of technology, whether in machine learning, business automation, or cloud-native services, can find a practical, reliable solution in Temporal. Adopting it helps you build systems that perform reliably in production and scale to meet today’s fast-moving demands.
