


Organizations operating in regulated sectors in the U.S. must balance development agility with strict FedRAMP compliance. However, many popular automation tools used in commercial clouds are not FedRAMP-authorized and therefore cannot be used when deploying workloads to the Azure Government Cloud (AGC).
To address this, we developed a custom Infrastructure-as-Code (IaC) framework built on Azure Bicep and Python orchestration, which ensures deployments are fully auditable, repeatable, and compliant.
What’s in this article:
- How we built an Infrastructure-as-Code (IaC) framework for FedRAMP-compliant deployments
- How the framework reduced provisioning to under two hours and eliminated configuration drift across 40+ microservices
Deployment Choices for AGC
Every environment in Azure Government Cloud requires strict adherence to security and compliance controls covering networking, resource governance, and identity management. Several approaches were considered for achieving automation under these constraints:
- Continue with manual deployments – An option that would technically keep us compliant, but at the cost of speed, efficiency, and reliability.
- Adopt a FedRAMP-compliant CI/CD platform – Tools like Azure DevOps Services (Gov), GitLab Ultimate (self-managed with FIPS), Jenkins on hardened images, or Harness Gov-ready edition are candidates. But they come with new costs, integration hurdles, and a steep learning curve, especially when the existing pipelines are already tightly bound to GitHub Actions in the commercial cloud.
- Build a custom automation framework – The framework would leverage Azure-native tooling, Infrastructure as Code, and orchestration logic to stay within compliance boundaries.
After evaluating the trade-offs, we recommend building a custom automation solution tailored to the client’s needs. This approach aligned with compliance and avoided the overhead of adopting a new CI/CD tool.
Mapping the Existing Infrastructure
Migrating existing workloads from Azure Commercial Cloud to AGC required a deep understanding of the current infrastructure landscape. To gain clarity, the team held inventory sessions to identify components and their dependencies and engaged service owners to map responsibilities and uncover hidden integrations. By the end of this exercise, we had mapped hundreds of components into a structured inventory. This blueprint gave us the clarity needed to design Infra Deployer, our automation framework that would power the migration.
How Infra Deployer Works
At its core, Infra Deployer combines Python orchestration with Azure Bicep templates to deliver secure, auditable, and repeatable infrastructure provisioning. It executes deployments in a containerized environment, giving us full control of runtime execution and ensuring that every step aligns with FedRAMP standards.
Architecture Overview
Infra Deployer is structured into three logical layers, each with a clear responsibility.
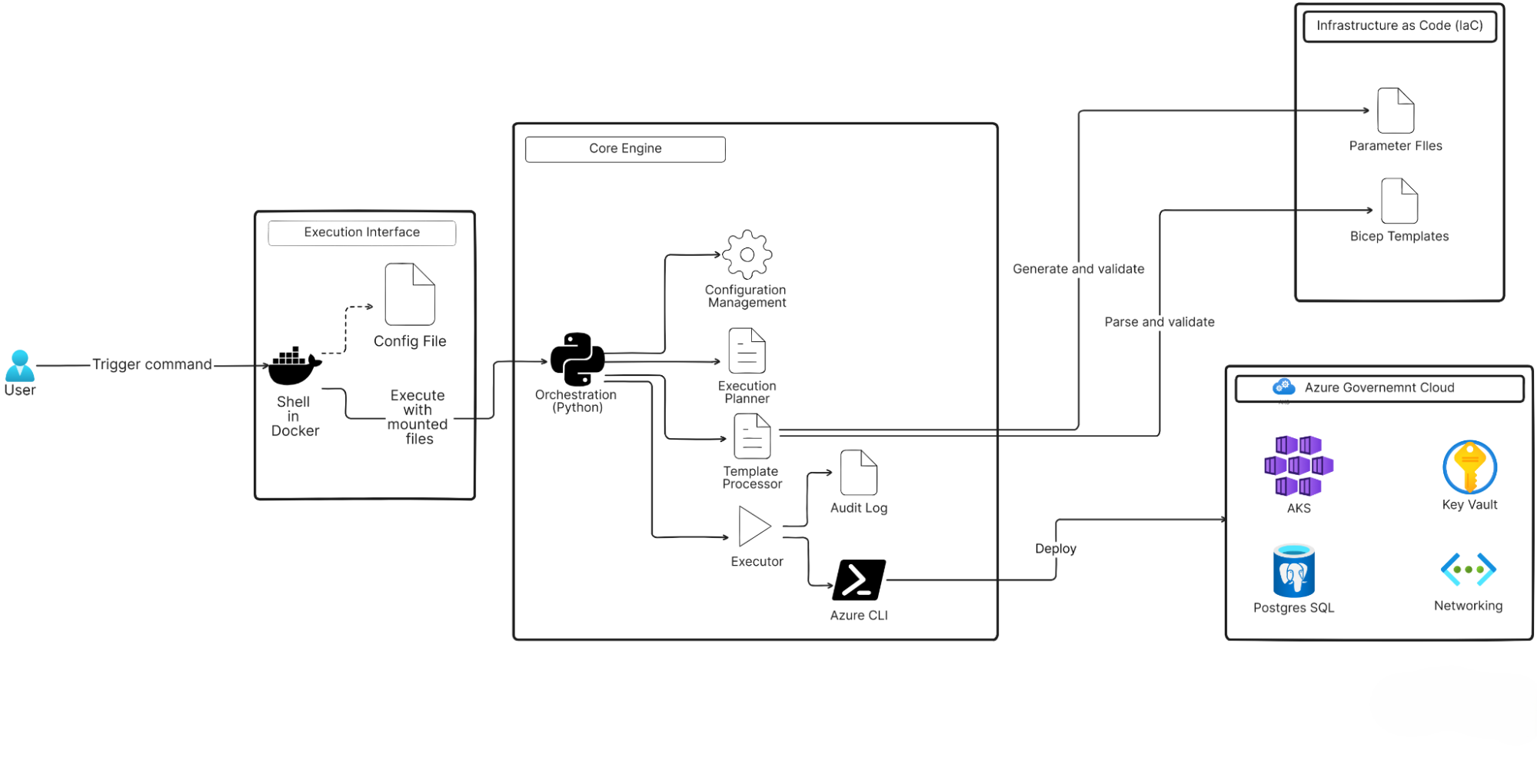
- Execution Interface
- Commands run inside a Docker container.
- Config files are mounted at runtime.
- Standardized runtime guarantees isolation and compliance.
- Core Engine
- Written in Python, this layer handles orchestration logic.
- Key components include the Configuration Manager, Template Processor, Execution Planner, Executor, and Azure CLI integration.
- Acts as the control plane for resource creation.
- Infrastructure Layer
- Azure Bicep templates with environment-specific parameters.
- Provides declarative, version-controlled resource definitions for everything from networks to AKS clusters.
This layered design gives Infra Deployer separation of concerns, flexibility to adapt workflows, and built-in compliance alignment.
Implementation Walkthrough
The next challenge was applying Infra Deployer to the client’s live workloads and ensuring that every deployment into Azure Government Cloud was not only compliant but also seamless for their teams.
The implementation happened in five stages:
1. Configuration Management
Deploying to both Azure Commercial and Government clouds introduces subtle but critical differences. Each environment uses different region names, subscription IDs, resource groups, and endpoints. Hardcoding these values or scattering them across scripts can quickly become unmanageable.
To tackle this, we created a single source of truth: a simple config.yaml file. This file defined everything that differed between environments, such as:
- Cloud Type
- Default subscription and resource group
- Location
- Directory paths for Bicep templates and parameter files
Together, these keys gave us a centralized, environment-aware control plane that allowed the same automation engine to work seamlessly across multiple Azure clouds.
We also needed a way to read, validate, and act on it during deployments. That’s where the Configuration Manager of our solution came in. It loads the config.yaml, makes sure all the required values are present, and prepares the environment for what comes next.
Under the hood, it provides a handful of critical methods:
load_config()to read and validate the YAML fileset_cloud()to select the correct Azure endpoint (Commercial, Government)az_login()to handle authenticationrun_az_command()to safely execute Azure CLI commands using the config values
By separating what to deploy (templates) from where to deploy (config), we ensured consistent, repeatable deployments across multiple Azure environments.
2. Dynamic Parameter Generation
Managing parameters across multiple environments is a common challenge in Infrastructure as Code (IaC). The Template Processor component solved this by automating parameter generation.
The Processor:
- Parses Bicep templates using regex to extract parameter names, types, and defaults.
- Cross-references parameters with the environment-specific YAML configuration file.
- Generates parameter files dynamically with defaults, environment values, or compound variables such as SSH keys.
- Supports federated identity mappings and dynamic role assignments.
3. Turning Workflows into Executable Steps
Once parameter management was automated by the Template Processor, the next step was orchestrating the deployment. We solved this with the Execution Planner, a component that reads workflow definitions from a YAML file and converts them into executable deployment steps.
The workflow file defines which resources to deploy, in what order, and with which dependencies. For example, a simple steps.yaml might provision a network, deploy an AKS cluster, and then configure monitoring.
For more complex scenarios, the workflow supports advanced controls like retries, error handling, and output management. Instead of just "deploy an AKS cluster," a workflow specifies how it should be deployed, which files to use, and what to do if it fails. Attributes like dependsOn ensure proper sequencing, while error handling enables self-healing with configurable retries.
Under the hood, the Execution Planner provides three core capabilities:
load_workflow()– Reads and validates the workflow YAML file.parse_steps()– Breaks down the workflow into individual, executable steps.workflow_path()– Ensures all file references (templates, parameters, scripts) are correctly located before execution.
Together with the Configuration Manager, the Execution Planner made Infra Deployer environment-aware and process-aware. The Configuration Manager manages the settings while Execution Planner manages the order of steps. This clean separation of concerns gave us flexibility: we could change environments with a simple tweak to config.yaml or adjust the workflow logic without modifying the infrastructure code itself.
4. Workflow Orchestration
The execution of each step defined in a deployment workflow is carried out by the Executor component.
The component handles three key responsibilities:
- Execution control – The
run()method manages the main execution loop, ensuring steps run in the correct order. - Step handling – The
execute_step()method converts YAML-defined actions into actual Azure resource deployments. - Dynamic adjustments – Methods such as
update_param_if_null()andupdate_with_custom_params()apply environment-specific or user-supplied values, ensuring deployments adapt without manual intervention.
By combining these capabilities, the Executor provides a structured, automated, and flexible execution layer. It validates parameters, injects required values, and applies overrides where necessary, delivering deployments that are consistent, auditable, and compliant across environments.
5. From Configuration to Provisioning
To standardize execution, we had Azure CLI, a wrapper around Azure CLI commands. This component formed the execution layer of Infra Deployer, ensuring that all operations are secure, reusable, and aligned with FedRAMP compliance across environments.
This approach was especially valuable for database access, where creating PostgreSQL roles and credentials can be error-prone.
By combining a custom Python script with Azure CLI, we automated database provisioning:
- Programmatically created PostgreSQL roles
- Randomly generated passwords and stored them securely in Azure Key Vault
- Consistently applied access policies across environments
Beyond database management, Azure CLI provides a standardized set of reusable operations, abstracting common CLI actions into reliable methods that eliminate repetitive scripting:
run_command()– Executes Azure CLI command securelylist_acr()– Lists container registries within a resource groupregister_provider()– Registers Azure resource providers when neededshow_provider_registration()– Verifies provider registration status for compliance
With these capabilities, every deployment, whether networks, AKS clusters, databases, or container registries, became part of a repeatable, auditable, and compliant workflow.
Outcomes and Impact
With Infra Deployer, we could provision a fully FedRAMP-compliant Azure Government Cloud environment in about two hours, with more than 30 resources deployed automatically. Every action was logged for audit purposes. Development, staging, and production environments were identical from day one.
| Metric | Result |
| Deployment Time | ~2 hours (end-to-end) |
| Resources Deployed | 30+ fully automated |
| Configuration Drift | 0% (identical across envs) |
| Audit Coverage | 100% automated logging |
Compliance was embedded from the start. Secrets were managed securely in Azure Key Vault, RBAC was enforced across deployments, and audit-ready logging required no additional effort. This approach eliminated configuration drift and reduced errors by more than 95 percent.
The impact was immediate. Teams onboarded faster because environments were operational in hours rather than days. Compliance requirements were met without slowing delivery, and the framework provided a repeatable model for scaling securely. Engineers could focus on innovation instead of manual provisioning, and the organization avoided the long-term risk of retrofitting security and compliance.
From a technical perspective, early validation of Bicep templates proved essential to catching issues before deployment. Automating every possible step minimized drift and errors, while consistent processes across environments preserved parity. Prioritizing security—especially managing secrets in Key Vault—paid dividends in stability and compliance.
The project demonstrated that organizations don't need to choose between agility and compliance. With the right automation design, both are possible.
