


If your enterprise is serious about Generative AI, the first question isn't "Which model should we use?" but rather "How ready is our data?"
AI is only as smart as the data it learns from. The quality, organization, and governance of that data determine whether AI becomes a business transformation engine or just another experiment. Achieving that level of AI readiness demands a consistent approach to data management, which a well-designed enterprise data platform can help enforce.
What's in this article:
- Why building an enterprise data platform remains complex even on modern hyperscalers
- How standardized, prebuilt data platform templates reduce design risk and delivery time
- Why these templates provide a faster, more reliable path to AI readiness
Why Building an Enterprise Data Platform Is Challenging
Cloud hyperscalers such as Azure, AWS, and GCP provide powerful building blocks for data platforms. However, the abundance of choice often increases architectural complexity.
Data teams must make foundational decisions, such as how:
- Data is ingested and orchestrated across batch and streaming pipelines
- Compute and storage are sized and tuned for performance and cost
- Security boundaries and governance policies are enforced consistently
- Legacy systems and modern tools are integrated into a single operating model
When these decisions are made independently by different teams or revisited for each new workload, the platform quickly becomes inconsistent, leading to systemic problems over time:
- Slow time to production as teams repeatedly rebuild core infrastructure and configurations.
- Governance drift as implementations diverge across environments, creating security gaps and compliance risks.
- Unstable cost and performance caused by poorly tuned compute and storage.
- Poor fit for specialized workloads such as IoT ingestion, real-time analytics, and AI pipelines.
- High integration overhead in multi-cloud environments with diverse data formats and tools.
These issues compound as the platform grows. Each new workload inherits the inconsistencies of the previous ones, making the platform harder to operate, govern, and evolve.
The absence of a standardized platform design is the root cause in almost every case. Long-term stability and scalability depend on establishing that standard early.
QBurst’s Managed Data Platform
Converge, QBurst’s Managed Data Platform, tackles these challenges by standardizing how enterprise data platforms are designed, deployed, and operated.
At the core of the platform is a library of reusable, application-specific architecture templates derived from real production systems and QBurst’s deep domain expertise. These templates encode the right data flows, infrastructure choices, governance controls, and performance configurations for each workload type. Each template is distilled from patterns that have worked in real projects, capturing practical, tested design choices.
For example, in IoT solutions, the template reflects the ingestion patterns, streaming requirements, storage tiers, and cost controls that the workload demands. Teams can start with an architecture that already matches the workload instead of retrofitting it later.
Using these templates, enterprise teams can provision a working data platform in a fraction of the time typically required by selecting the appropriate architecture and applying it to their cloud environment.
Platform Capabilities
- Application-Specific Templates: Predefined architectures for workloads such as IoT, streaming analytics, batch processing, and AI pipelines. These pre-built templates are derived directly from our deep domain expertise.
- Flexible Technology Models: Support for open-source stacks, managed cloud services, or a combination across single-cloud and multi-cloud environments.
- Infrastructure as Code: All components are provisioned using Terraform, enabling consistent, repeatable deployments across environments.
- Embedded Platform Standards: Security, governance, access control, cost management, scaling, and reliability are built into the platform design.
QBurst operates and maintains the platform in production, managing costs based on data and compute usage, planning capacity, and continuously tuning performance.
Example: Implementing a Data Platform on Azure with Databricks
To illustrate how these templates work in practice, consider the case of one of our large retail clients who migrated to a unified platform using Azure and Databricks.
Before the transformation, transactional data resided in multiple legacy systems. Analytics ran on a traditional data warehouse, and machine learning teams used separate tools for feature engineering, training, and deployment. Orchestration was handled by disparate services, leaving limited end-to-end visibility. This fragmentation slowed delivery, increased operational costs, and complicated governance.
We restructured the platform into a single execution environment.
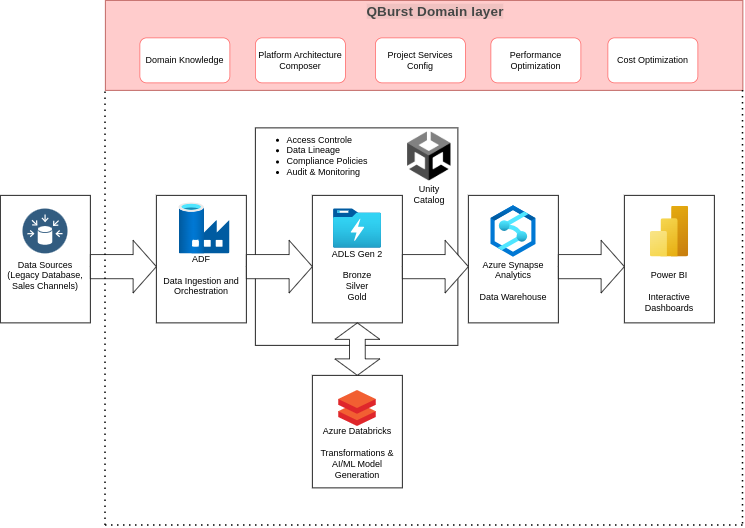
- Ingestion and Orchestration: Data from legacy systems and real-time sales channels was centralized in a unified data lake, with batch and streaming pipelines coordinated through Azure Data Factory.
- Transformation and Enrichment: Raw datasets were processed in Azure Databricks using a medallion architecture. Progressive validation, cleansing, and enrichment produced reliable datasets suitable for analytics. This creates a trusted "single source of truth" that fuels decision-making.
- Analytics and AI Enablement: Business teams access governed datasets through Azure Synapse and Power BI. Data science teams trained and deployed models in Databricks notebooks, supporting use cases such as personalized marketing and inventory optimization.
- Unified Governance and Security: Finally, with Unity Catalog, compliance and security policies are embedded at every stage, giving the client confidence that their sensitive data follows rigorous enterprise standards without slowing innovation.
While this implementation used Azure and Databricks, the underlying design patterns come from the templates themselves. The same approach standardizes ingestion, transformation, governance, and operational controls across cloud providers and workload types.
Impact on Delivery and AI Readiness
By applying standardized templates and a managed operating model, enterprises can reduce the time spent assembling core infrastructure and stabilizing the platform. Platform environments can be provisioned with consistent security, governance, and performance controls, allowing data pipelines to reach production with fewer iterations.
With data engineering teams spending less time stabilizing pipelines and data science teams working on governed, production-ready datasets from the start, models can be trained, validated, and deployed without repeated delays from platform rework or integration issues. The platform ensures that each stage of the AI lifecycle (data preparation, feature engineering, model testing, and deployment) proceeds on a reliable foundation, accelerating the delivery of insights.

