


Most software development teams, including mine, rely on cloud infrastructure to achieve the performance and scalability demanded by modern applications. While the cloud offers clear benefits for production workloads, the reality is different for non-production workloads such as development, staging, and POCs. These environments are often inefficient and drive up costs without contributing to revenue.
The Reality Behind Non-Prod Workloads
We operate multiple production and non-production workloads across various cloud platforms. As our projects grew, we noticed a significant increase in cloud spending, which prompted us to take a closer look at what was happening. A detailed analysis revealed that nearly 60% of our cloud expenses were tied to non-production and POC environments.
We needed a flexible and cost-efficient non-prod infrastructure to support active development and experimentation. The solution we identified was to migrate non-critical workloads to an on-premise environment, adopting a hybrid architecture that combines both on-premise and cloud resources.
Our Non-Prod Infrastructure Approach
We started by auditing our available on-prem resources, documenting the specs, current condition, and performance potential. In parallel, we worked closely with project teams to map the architecture, tooling, and runtime needs of each non-production workload. With every team running different stacks and deployment models, this alignment was critical.
Based on those inputs, we designed and deployed an on-prem setup tailored to support development, testing, and POC activities without compromising flexibility, performance, or security.
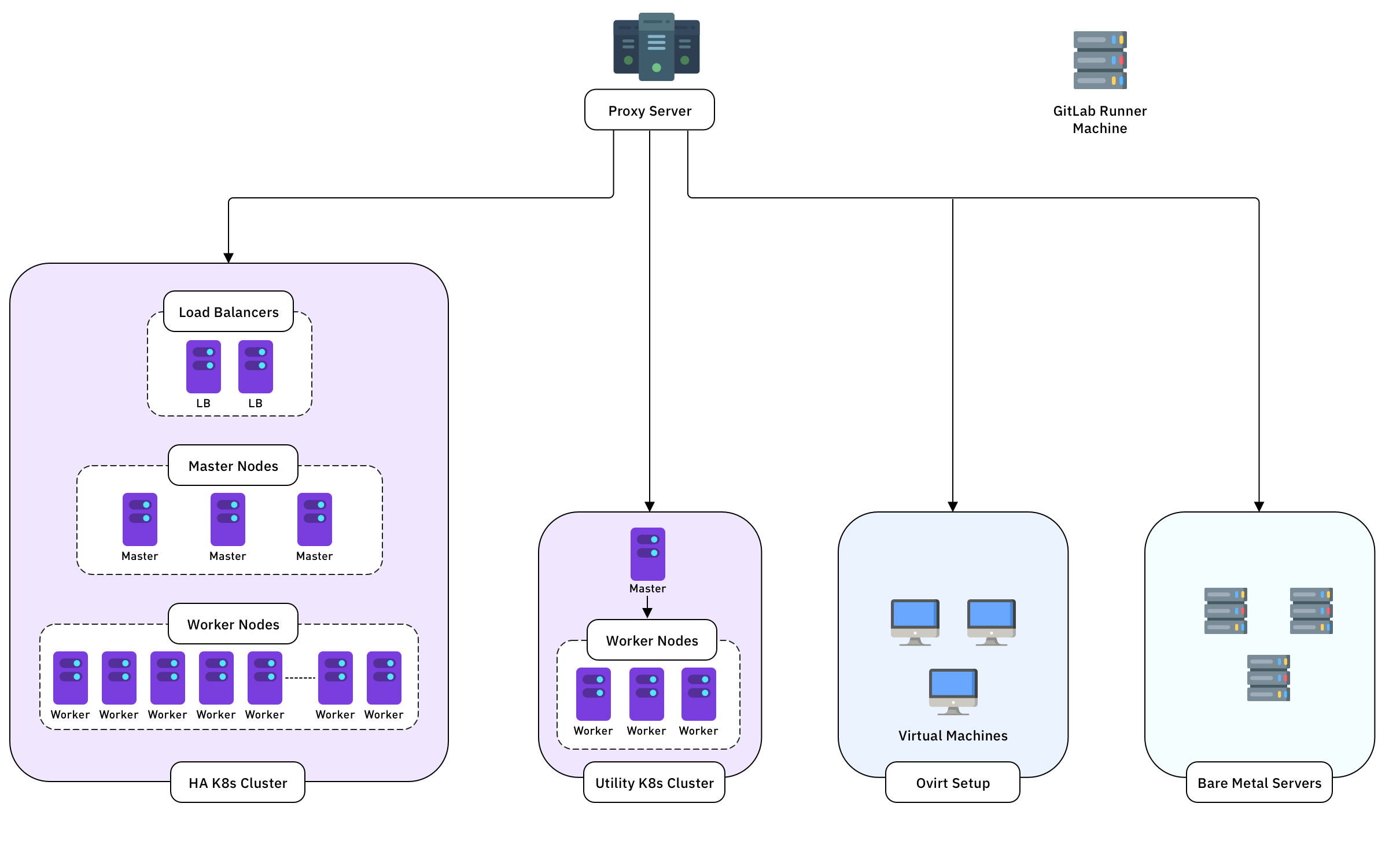
Here’s how we approached the key components.
Kubernetes on Bare Metal
Since many of our projects are built on containers, Kubernetes was a natural foundation for our on-prem environment. We opted to run Kubernetes directly on bare metal to maximize performance and reduce virtualization overhead.
This setup demanded careful planning around availability, access controls, and security. We also learned that combining infrastructure testing with non-prod application workloads in a single cluster can lead to unnecessary risks. Isolating environments based on workload type and usage proved to be far more reliable and maintainable.
Lightweight Kubernetes Cluster for DevOps and POCs
To support various testing and POC activities, we found it best to maintain an independent Kubernetes cluster. Using minimal resources, we bootstrapped the cluster with kubeadm, keeping the setup lightweight yet functional. This isolated cluster is used for testing CI workflows, evaluating open-source tools, and applying version upgrades or security patches, without interfering with other environments.
High Availability Cluster for Non-Prod Environment
For more stable non-prod environments such as staging or QA, we prioritized availability. Rather than setting up a basic cluster, we opted for a multi-master architecture with load balancers in front. This setup ensures that the environment remains operational even if a master node or the load balancer goes down.
Improving Accessibility and Governance
To improve accessibility and management of Kubernetes clusters, we developed a custom dashboard application integrated with Role-Based Access Control (RBAC).
This custom dashboard supports:
- Credential generation for secure user access
- Role-based access management
- Resource listing and real-time status monitoring
- Onboarding instructions for new users
(The native Kubernetes dashboard application can also be used to configure and troubleshoot the cluster. However, because it grants significant control over the environment, access has to be limited to cluster administrators and DevOps engineers only.)
Admission Control for Better Resource Management
To enforce consistency and control in how resources are provisioned, we implemented admission controllers using Kyverno. This gave us a policy-driven way to manage cluster usage.
Examples of Kyverno policies we applied:
- Enforcing maximum CPU and memory usage per namespace
- Requiring all pods and deployments to specify resource requests and limits
- Allowing container images only from approved registries
These policies help us prevent over-provisioning, reduce waste, and ensure more predictable behavior across non-prod workloads. They also play a key role in maintaining basic security by limiting what can run in the cluster.
NGINX Ingress Controller with MetalLB
For exposing internal services within our on-prem environment, we combined:
- NGINX Ingress Controller for managing HTTP/S endpoints and routing rules.
- MetalLB as a lightweight on-prem load balancer to assign external IPs to services.
This allowed us to simulate a cloud-like ingress experience with minimal overhead and cost.
Bare Metal Workloads and Virtualization
To balance performance with efficient resource use, we adopted a hybrid model, assigning workloads to either bare metal or virtual machines based on their specific needs.
- Bare metal servers handle high-performance workloads like databases and low-latency applications that need consistent, low-overhead compute.
- oVirt-managed virtual machines support early-stage development and testing. The centralized, browser-based interface simplifies provisioning and management, making it ideal for fast, lightweight experimentation.
Supporting Components
Prometheus-Grafana Integration for Observability
We integrated Prometheus with Grafana to gain full visibility into cluster performance, resource consumption, and application health. Prometheus collects real-time metrics from the infrastructure while Grafana visualizes them through interactive dashboards.
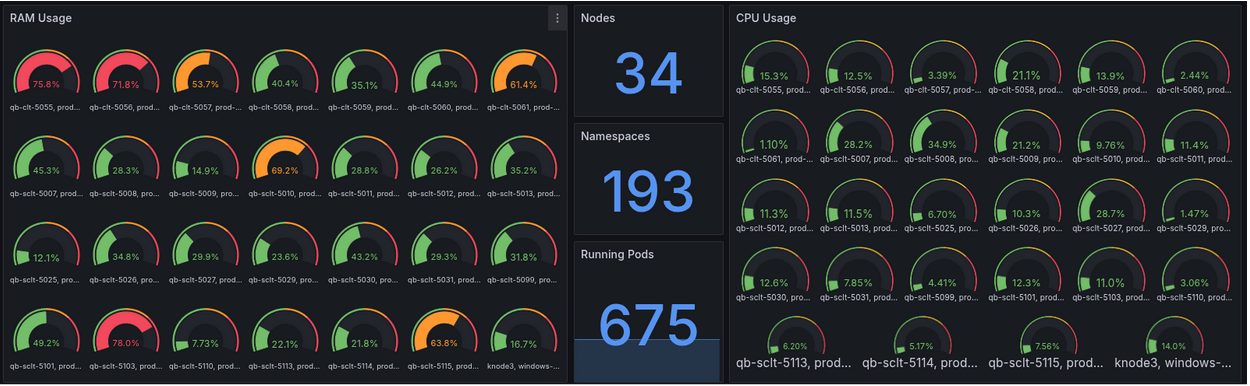
Logging with the ELK Stack
We integrated the ELK Stack for critical apps that require detailed log access and long-term retention. For other workloads, we enabled RBAC-controlled command-line log access. This provides a lightweight, secure way to retrieve logs without placing additional load on the logging infrastructure.
On-Premise Runner Nodes
With our development environment hosted locally, we needed dedicated runner nodes for smooth CI/CD execution. We tagged each runner to route jobs precisely to the relevant environment and application. To support different workloads, we used a mix of Docker-based machine runners and Kubernetes-based executors. This setup allowed us to balance performance with a high degree of control over CI/CD workloads.
Early Development Security Analysis
We integrated security checks to catch issues before they reached production. We set up a self-hosted SonarQube instance for static application security testing (SAST), which helps us enforce code quality standards, track technical debt, and monitor code coverage. (We’re also exploring open-source solutions such as Mixeway.)
Uptime Monitoring and Alerting
To ensure system reliability, we built a custom uptime monitoring tool. We also recommend using open-source health check solutions to track endpoint availability.
Our custom setup includes:
- Google Chat webhook alerts that send real-time notifications when services go down.
- Alertmanager, integrated with Prometheus and Grafana, to define alert rules and trigger notifications based on infrastructure metrics for Kubernetes workloads and bare metal servers.
Automating On-Prem Management with Ansible
We adopted Ansible to automate on-premises tasks like software installs, updates, and password rotations. Using playbooks, we ensured consistent configuration across machines and reduced manual effort. This automation is key in scaling and maintaining our infrastructure as it grows.
Internal Proxy Server for URL Accessibility
To simplify access across the internal network, we implemented a proxy server with path-based routing. This setup allows each application, even in a non-prod environment, to have a globally accessible URL reachable via internal network or VPN.
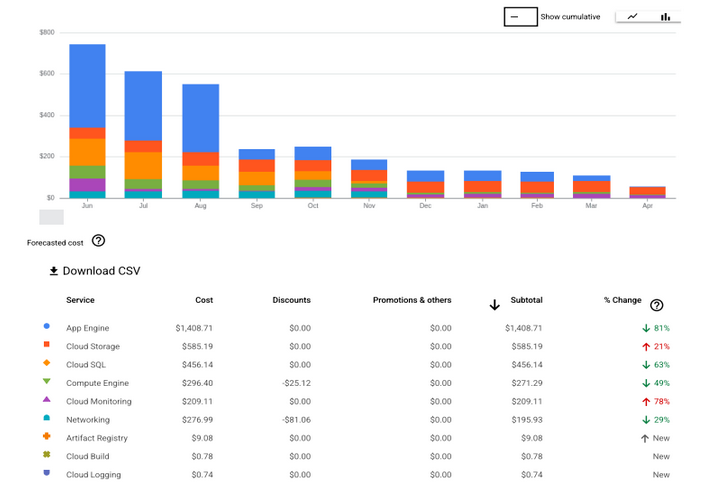
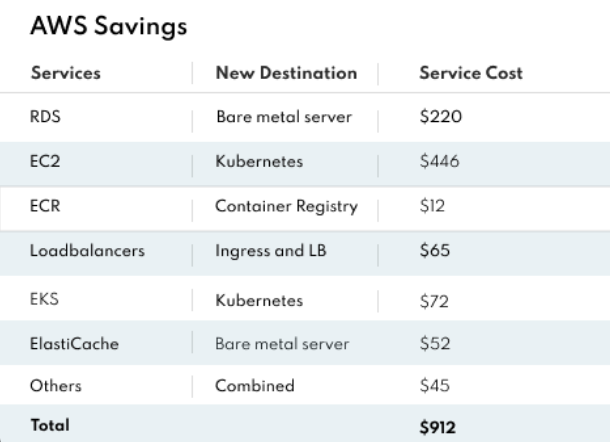
Cost Savings After Migrating Non-Prod to On-Prem
After shifting select workloads from public cloud to on-premise infrastructure, we conducted a cost analysis to measure the impact. The results were significant:
- AWS migration: Our projects previously relied on services like RDS, EC2, EKS, Elastic Load Balancers, and ElastiCache. By mapping each to equivalent on-prem solutions, we reduced our monthly AWS costs by approximately $950.
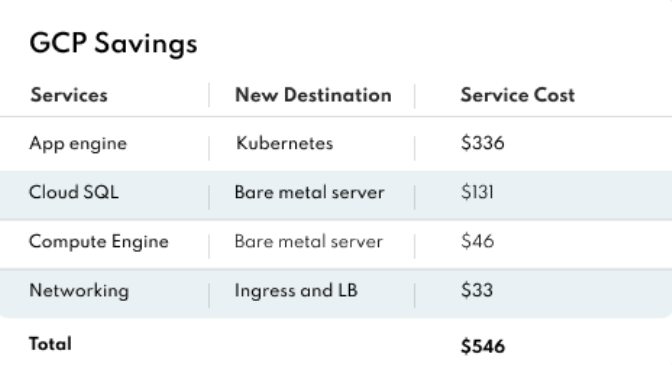
- Google Cloud migration: Workloads primarily leveraged App Engine, Cloud SQL, Compute Engine, and Load Balancers. The migration resulted in monthly savings of around $520.
In addition to these migrations, we’ve also started deploying new POC projects directly to the on-prem environment. This contributes further to our overall savings.
What We Learned
A major realization was that we had a lot of underutilized on-prem infrastructure. Once properly assessed and managed, this idle infrastructure became a valuable asset for hosting non-production workloads.
However, this approach isn’t without challenges. Running an on-prem Kubernetes cluster needs a dedicated operations team and strong expertise in Kubernetes and networking. Without the right skills and support, maintaining the setup can be difficult.
In our case, the cost savings justify the effort. Automating key processes and restricting on-prem to non-critical and low-risk environments makes it sustainable in the long run.
