


Setting Up the Cluster in Azure HDInsight
Note: If you are familiar with the Azure HDInsight setup process, feel free to jump to the section on Executing Spark Job. To set up the cluster, log into the Azure portal and choose Create a resource and select HDInsight under Analytics. This should guide you through a 3-step wizard (if you choose to leave the advanced settings at its default) for the cluster setup.
This should guide you through a 3-step wizard (if you choose to leave the advanced settings at its default) for the cluster setup.
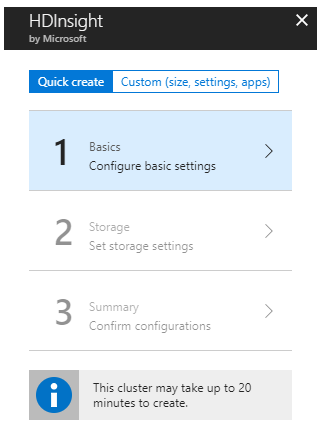 A few points to note while setting up the cluster:
Step 1 - While setting the cluster configuration in the Basic Settings, ensure that the Cluster type is set to Spark. Also, choose a location that already has a storage account under the same subscription.
Note: Keep a record of the admin and ssh usernames and the password entered as they will be required later for executing the Spark job.
A few points to note while setting up the cluster:
Step 1 - While setting the cluster configuration in the Basic Settings, ensure that the Cluster type is set to Spark. Also, choose a location that already has a storage account under the same subscription.
Note: Keep a record of the admin and ssh usernames and the password entered as they will be required later for executing the Spark job.
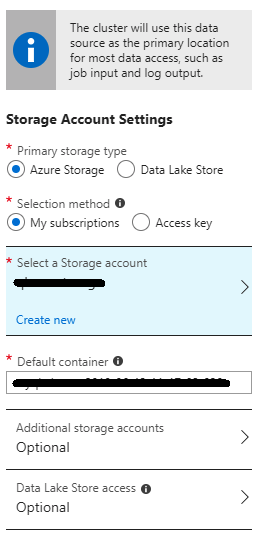
 Step 2 - In the Storage Settings, choose a storage account (we will go with Azure Blob Storage option) and provide a container name. This container will be used as the distributed file storage for the cluster using the WASB (Windows Azure Storage Blob) abstraction built on top of HDFS. The cluster will have private access for the container and will be used to store and read all files required for processing.
Step 2 - In the Storage Settings, choose a storage account (we will go with Azure Blob Storage option) and provide a container name. This container will be used as the distributed file storage for the cluster using the WASB (Windows Azure Storage Blob) abstraction built on top of HDFS. The cluster will have private access for the container and will be used to store and read all files required for processing.
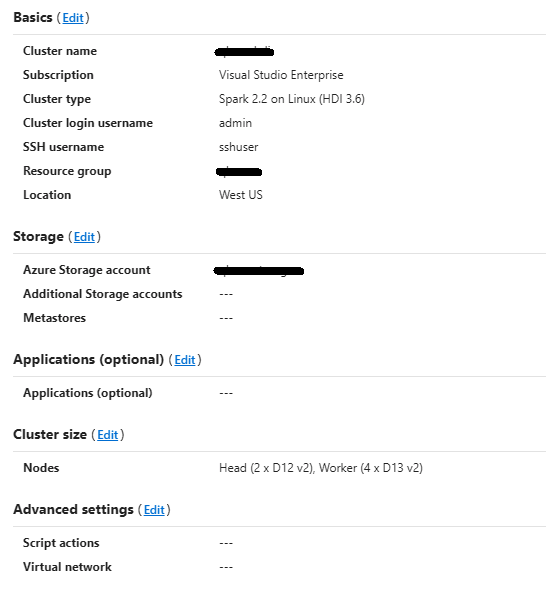
 Step 3 - In the final configuration confirmation screen, there is an option to edit the cluster size and/or the node configurations to suit the anticipated processing resource requirements of the application. The default size is 6 nodes (2 head nodes and 4 workers). Go ahead and click Create to proceed with the default cluster size.
Step 3 - In the final configuration confirmation screen, there is an option to edit the cluster size and/or the node configurations to suit the anticipated processing resource requirements of the application. The default size is 6 nodes (2 head nodes and 4 workers). Go ahead and click Create to proceed with the default cluster size.
Tip: Since the cluster will be billed on an hourly basis for the duration of time it is up, deleting the cluster when it is not in use for an extended period of time will help save on costs. The associated file storage container will not be deleted and can be linked back as the storage container while setting up a new cluster next time.
Executing Spark Job
Now that we have the cluster up and running, let’s go ahead and create a Spark job. We will be using a Python Spark (PySpark) script. (For the sake of brevity, we have provided a stripped-down, simplified version of the original script here.) The script along with a sample input file is attached below: LogParser.txt (Rename as LogParser.py after downloading.) Logdata.csv We will not attempt to trace the script line by line here. At a high level, the script accepts and reads an input log file path and output folder path as parameter (lines 18-25), maps the line by line data from the input log file into an RDD (line 27), aggregates the events by adding up their number of occurrences, and sorts the final data collected into a list (lines 28-29). Finally, the data is saved into a file folder under the output path passed as argument.
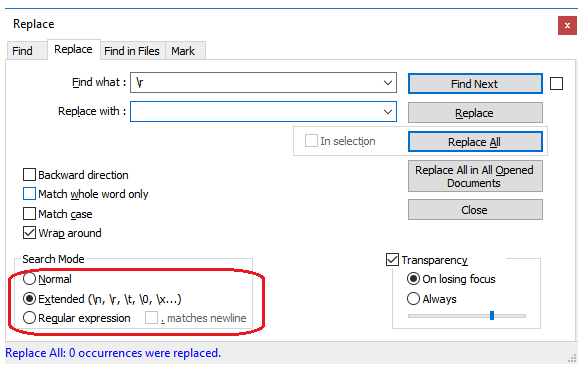
Tip: If a Windows machine is used to create/edit the Python script, ensure that the Windows new line characters (\r\n) are replaced with Linux new line characters (\n) as the cluster machines running the Spark jobs are Linux-based. Failing to do so will result in execution failure without proper error messages or hints. A tool like notepad++ may be used to do this as shown below.
 To execute the script, follow these steps:
1. Copy the script file into the cluster. To do this, first, download the LogParser.py script and the logdata.csv input file into a local folder and use the windows pscp command from the folder to transfer them into the HDInsight cluster as follows:
Pscp LogParser.py <<sshusername>>@<<hdiclustername>>-ssh.azurehdinsight.net:
Enter the password when prompted for, following which the files will be transferred as shown below.
To execute the script, follow these steps:
1. Copy the script file into the cluster. To do this, first, download the LogParser.py script and the logdata.csv input file into a local folder and use the windows pscp command from the folder to transfer them into the HDInsight cluster as follows:
Pscp LogParser.py <<sshusername>>@<<hdiclustername>>-ssh.azurehdinsight.net:
Enter the password when prompted for, following which the files will be transferred as shown below.
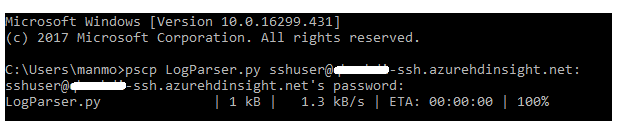
Tip: Filenames are case-sensitive in Linux and hence the transferred files will have the same case as that provided while transferring the files using the pscp command. Hence, in the above case, logparser.py will yield a “file not found” error, whereas LogParser.py will run fine when trying to execute the script.
2. Connect to the HDInsight cluster through SSH (with a tool like PuTTY) using the ssh username and password configured in Step 1 of the cluster setup.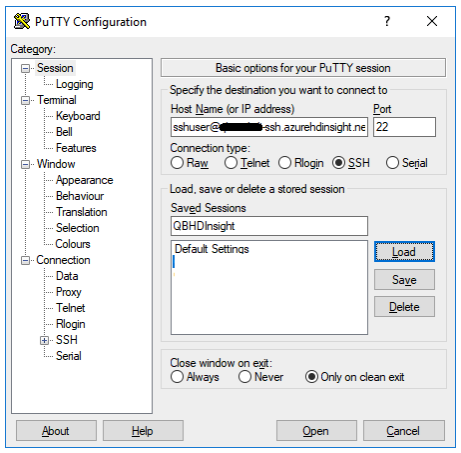 Once in the terminal, running the ‘ls’ command can list and ensure the presence of the transferred script file.
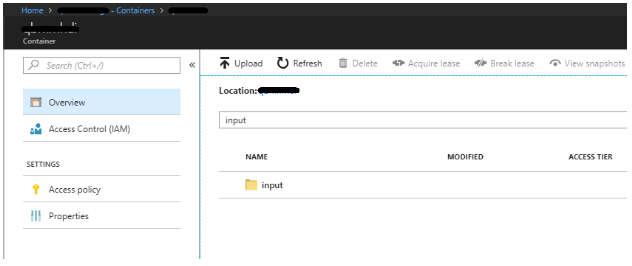
3. Spark expects the input and output paths to be relative to the storage container associated with the cluster (refer Step 2 of the cluster setup). Upload the input file to a path under the blob storage container as shown below.
Once in the terminal, running the ‘ls’ command can list and ensure the presence of the transferred script file.
3. Spark expects the input and output paths to be relative to the storage container associated with the cluster (refer Step 2 of the cluster setup). Upload the input file to a path under the blob storage container as shown below.
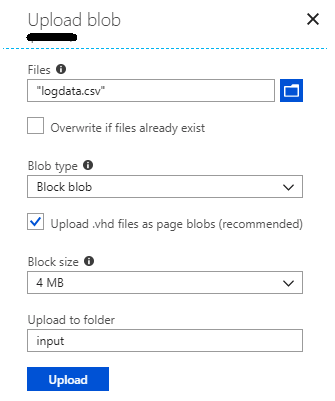 The full path for the file would look like: https://<<storageaccount>>.blob.core.windows.net/<<container>>/input/logdata.csv
The full path for the file would look like: https://<<storageaccount>>.blob.core.windows.net/<<container>>/input/logdata.csv
 4. Submit the script to Spark for execution using the spark-submit command, as shown below:
spark-submit <<scriptfile>>
In our case, since the script expects an inputfile and outputpath as parameters, the syntax for execution will be
4. Submit the script to Spark for execution using the spark-submit command, as shown below:
spark-submit <<scriptfile>>
In our case, since the script expects an inputfile and outputpath as parameters, the syntax for execution will be

 Now that we are familiar with setting up a Hadoop cluster on Azure HDInsight and submitting and executing a Spark job in a distributed manner on the cluster using command line, we will look at how this process can be automated and orchestrated as part of a bigger data processing workflow. For any practical purpose, it will be essential that such jobs are executed as part of a workflow, defined to run on a scheduled basis unless the requirement is for a one-time processing need.
In the next part of this series, we will go into how Azure Data Factory can be used to schedule and orchestrate extraction of data from Azure Table Storage, process it using Spark on HDInsight, and finally push the processed output to an Azure SQL database for storage and reporting purposes.
Now that we are familiar with setting up a Hadoop cluster on Azure HDInsight and submitting and executing a Spark job in a distributed manner on the cluster using command line, we will look at how this process can be automated and orchestrated as part of a bigger data processing workflow. For any practical purpose, it will be essential that such jobs are executed as part of a workflow, defined to run on a scheduled basis unless the requirement is for a one-time processing need.
In the next part of this series, we will go into how Azure Data Factory can be used to schedule and orchestrate extraction of data from Azure Table Storage, process it using Spark on HDInsight, and finally push the processed output to an Azure SQL database for storage and reporting purposes.