This post is part of our continuing blog series on the Internet of Things. In our previous posts, we discussed sensors, wireless technologies in IoT, and Connected Operations: 3 IoT Scenarios.
Smart cities, self-driving cars, intelligent machines—the IoT market is exploding with “Things.” The ease with which they cross over from sci-fi to real life makes it look like a breeze, thanks in part to data engineers who do the heavy lifting behind the scenes.
Take the case of a smart factory outfitted with IP-enabled surveillance cameras. For every camera, the factory has 70 GB highly compressed data to deal with every day. In a wind farm, a single turbine could generate 1-5 TB data every day. With scores of devices churning data every second, it is doesn’t take long for data to become really unwieldy.
It’s not just the humongous data that poses a challenge but also its diversity and velocity. For IoT applications to come together, data streamed by disparate devices have to be made available in a useful form. Dealing with IoT data, which is diverse, real-time, and high-stream is no small feat. Data engineers have their hands full with tasks ranging from data ingestion, integration, processing, and storage. A range of frameworks, starting with Apache Hadoop, comes to their help.
IoT Data System Architecture
A generalized IoT data framework looks like this:
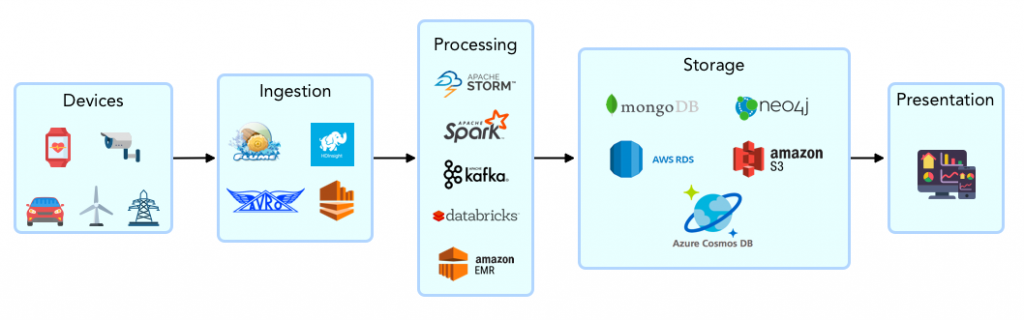 Data is generated by diverse devices or the intermediate data stores that are linked to the devices. It is ingested into a central processing and analytics platform. Data is ingested either in streams or in batches and is transformed as it flows through the pipeline. The transformed data is stored in various data stores or served to analytics applications in real time. At the far end of the spectrum, visualization tools help end users access this data.
It is obvious that data engineering involves a medley of tools and approaches. Choosing the right ones based on data volume, format, throughput requirements, and so on, is where a data engineer’s skill comes into play. More on each of these stages below:
Data is generated by diverse devices or the intermediate data stores that are linked to the devices. It is ingested into a central processing and analytics platform. Data is ingested either in streams or in batches and is transformed as it flows through the pipeline. The transformed data is stored in various data stores or served to analytics applications in real time. At the far end of the spectrum, visualization tools help end users access this data.
It is obvious that data engineering involves a medley of tools and approaches. Choosing the right ones based on data volume, format, throughput requirements, and so on, is where a data engineer’s skill comes into play. More on each of these stages below:
Data Ingestion
Data ingestion is the first step in data engineering. Data from diverse sources are brought to a central IoT platform that can handle huge volumes of data. While designing the ingestion process, the data engineer takes into consideration various factors like diversity in data formats and speed of data. Something else the data engineers have to account for is the late arrival of data due to connectivity issues at device location.
In batch ingestion, a chunk of data is pushed into the data pipeline at intervals. The data engineer looks at the various data sources and the knowledge output expected from the data and plans the ingestion process accordingly. Prioritizing data sources, validating at the source, routing to the correct stage of data pipeline are some of the tasks involved. Again, they must take into account factors like data velocity, volume, formats, and mode of ingestion required.
Big data systems use optimized data serialization technologies like Apache Avro. While allowing rich data structure, Avro provides compact and fast binary serialization format. It can be easily serialized into a file and can support remote procedure calls (RPC). It provides for easy interface creation in high-level languages. An alternative is Apache Thrift.
Data Plumbing and Processing
The ingested data flows through a network of pipes. Apache Kafka, a high-performance streaming data message broker, is a key actor here. Data is streamed to various processing nodes that receive and transform the input data, creating new datasets. While Kafka defines the pipelines and routes the data between processing nodes, it does not process data. That job is done by tools such as Apache Spark and Apache Storm.
Many IoT systems require real-time or near real-time processing of data. Some of the leading frameworks for real-time processing are Apache Spark, Apache Storm, and Apache Flink. Storm works only with streaming data and achieves very low latency. It supports processing instructions in a variety of modern programming languages. Spark and Flink support both batch and stream processing but they approach stream processing differently. While Spark processes data in micro-batches, Flink processes data as it arrives.
Data Storage
IoT data presents challenges for storage on multiple counts. First its very nature—heterogeneity, speed, and capacity to scale. Concerns about data quality and security need to be satisfactorily addressed. Then, based on business requirements, there are trade-offs to be made—between availability and consistency, between consistency and latency. Above all, there are cost considerations.
To analyze historical data, create data models, and draw contextualized insights, it is important that all the data is stored somewhere. For real-time analysis, the write has to be transferred to the database as soon as it originates from the device and in the very order that it originated. Performance of traditional databases takes a hit when there is a surge in write requests.
For performance at scale and efficient storage, NoSQL databases, designed for massive storage and parallel processing, are quite often a better fit than Relational Database Management Systems (RDBMS). Among them, columnar databases have a certain edge in analytical operations because of their column-oriented data storage, which enables fast aggregation. Data stored in columnar parquet format can be accessed from Hadoop, GCP, and Azure.
Edge Computing in IoT
A large portion of computing in IoT can happen at the edge, that is, within infrastructure closer to the IoT device rather than in the cloud. While intelligent edge computing systems with the capacity to store, compute, and analyze data on their own close to the data source are still not widespread, they are set to rise in the near future. When this happens, industrial IoT would become more viable as it helps reduce the cost of transmission and increase the speed to insights and action.
Choose Wisely!
Given the plethora of tools and frameworks available, data engineering calls for careful judgment, a sort of balancing act even. Without this deft planning and balancing, IoT applications cannot deliver on their promise of cutting-edge analytics or real-time action. It is a skill that our data engineers demonstrate every time we give shape to an IoT application, be it for healthcare or wind energy, home automation or worker safety.



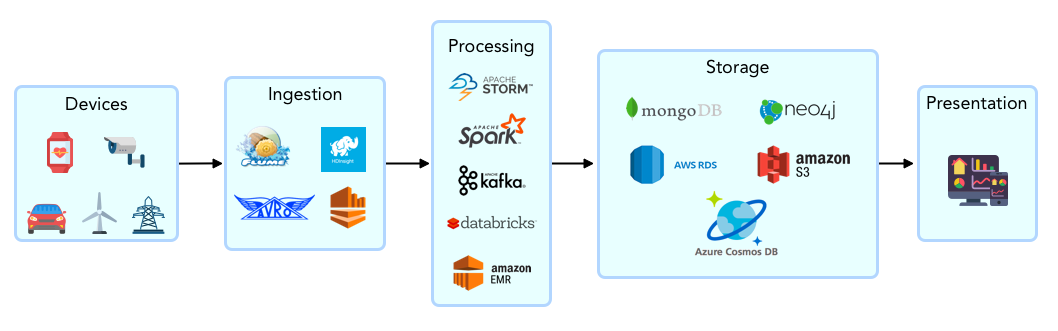 Data is generated by diverse devices or the intermediate data stores that are linked to the devices. It is ingested into a central processing and analytics platform. Data is ingested either in streams or in batches and is transformed as it flows through the pipeline. The transformed data is stored in various data stores or served to analytics applications in real time. At the far end of the spectrum, visualization tools help end users access this data.
It is obvious that data engineering involves a medley of tools and approaches. Choosing the right ones based on data volume, format, throughput requirements, and so on, is where a data engineer’s skill comes into play. More on each of these stages below:
Data is generated by diverse devices or the intermediate data stores that are linked to the devices. It is ingested into a central processing and analytics platform. Data is ingested either in streams or in batches and is transformed as it flows through the pipeline. The transformed data is stored in various data stores or served to analytics applications in real time. At the far end of the spectrum, visualization tools help end users access this data.
It is obvious that data engineering involves a medley of tools and approaches. Choosing the right ones based on data volume, format, throughput requirements, and so on, is where a data engineer’s skill comes into play. More on each of these stages below:
