


Logs in any computing program can be used to track its execution and how it is faring at the moment. Based on my experience here at QBurst, let me show you how to make meaningful logs in any backend application with proper contextual information. This post will specifically take a look at logging in Java and see how logs can be made meaningful, and then go on to introduce Mapped Diagnostic Context (MDC) logging.
Take a look at the log excerpts from a website’s backend server that received requests to save a user setting from two users at the same time:
2020-04-09T15:29:53.910Z DEBUG MyLogger.doFilterInternal(45) - POST HTTP/1.1 /users/settings/save 2020-04-09T15:29:53.922Z INFO MyService.performAction(181) - Try save user setting 2020-04-09T15:29:53.951Z DEBUG MyInterceptor.log(27) - --> GET http://www.example.com/save/user?id=1832 2020-04-09T15:29:53.990Z DEBUG MyLogger.doFilterInternal(45) - POST HTTP/1.1 /users/settings/save 2020-04-09T15:29:54.009Z INFO MyService.performAction(181) - Try save user setting 2020-04-09T15:29:54.030Z DEBUG MyInterceptor.log(27) - --> GET http://www.example.com/save/user?id=983 2020-04-09T15:29:56.222Z DEBUG MyInterceptor.log(31) - <-- 200 OK Saved 2020-04-09T15:29:56.235Z INFO MyService.performAction(201) - Saved user setting 2020-04-09T15:29:56.472Z DEBUG MyInterceptor.log(31) - <-- 200 OK Saved 2020-04-09T15:29:56.481Z INFO MyService.performAction(201) - Saved user setting
We have marked the logs for the user with id 1832 above. But when there are more users or more logs, identifying the logs of a particular user can be difficult. We can log the user ids too and that seemed to be sufficient, or so we thought.
2020-04-09T15:29:53.910Z DEBUG MyLogger.doFilterInternal(45) - POST HTTP/1.1 /users/settings/save 2020-04-09T15:29:53.922Z INFO MyService.performAction(181) - Try save user setting with id: 1832 2020-04-09T15:29:53.951Z DEBUG MyInterceptor.log(27) - --> GET http://www.example.com/save/user?id=1832 2020-04-09T15:29:53.990Z DEBUG MyLogger.doFilterInternal(45) - POST HTTP/1.1 /users/settings/save 2020-04-09T15:29:54.009Z INFO MyService.performAction(181) - Try save user setting with id: 983 2020-04-09T15:29:54.030Z DEBUG MyInterceptor.log(27) - --> GET http://www.example.com/save/user?id=983 2020-04-09T15:29:56.222Z DEBUG MyInterceptor.log(31) - <-- 200 OK Saved 2020-04-09T15:29:56.235Z INFO MyService.performAction(201) - Saved user setting with id: 1832 2020-04-09T15:29:56.472Z DEBUG MyInterceptor.log(31) - <-- 200 OK Saved 2020-04-09T15:29:56.481Z INFO MyService.performAction(201) - Saved user setting with id: 983
We can see the limitation of this solution, if say, we want to distinguish between the two log traces of the same user that happened at about the same time:
2020-04-09T15:29:53.910Z DEBUG MyLogger.doFilterInternal(45) - POST HTTP/1.1 /users/settings/save 2020-04-09T15:29:53.922Z INFO MyService.performAction(181) - Try save user setting with id: 983 2020-04-09T15:29:53.951Z DEBUG MyInterceptor.log(27) - --> GET http://www.example.com/save/user?id=983 2020-04-09T15:29:53.990Z DEBUG MyLogger.doFilterInternal(45) - POST HTTP/1.1 /users/settings/save 2020-04-09T15:29:54.009Z INFO MyService.performAction(181) - Try save user setting with id: 983 2020-04-09T15:29:54.030Z DEBUG MyInterceptor.log(27) - --> GET http://www.example.com/save/user?id=983 2020-04-09T15:29:56.222Z DEBUG MyInterceptor.log(31) - <-- 200 OK Saved 2020-04-09T15:29:56.235Z INFO MyService.performAction(201) - Saved user setting with id: 983 2020-04-09T15:29:56.472Z DEBUG MyInterceptor.log(31) - <-- 200 OK Saved 2020-04-09T15:29:56.481Z INFO MyService.performAction(201) - Saved user setting with id: 983
So there it was—we can no longer distinguish between the two logs traces here. We had to look at it in a different way. To address the problem, we thought of adding to the log an identifier corresponding to every other HTTP request hitting our server. We can create such an identifier for each request to distinguish the context, but it would make the log more verbose as we’d have to repeat that for all the logs.
This brought us to Mapped Diagnostic Context (MDC), which does most of the work behind the scenes with little intervention from the developer.
Let's see how to set up MDC in a Java Spring Boot project. If you are using Log4j or SLF4j/Logback you can use:
MDC.put("myProp", "contextValue");
If you are using Log4j2 you can use:
ThreadContext.put("myProp", "contextValue");
Now, retrieve "myProp" in the log pattern using %X{myProp}. For example, you can use this:
%date{yyyy-MM-dd'T'HH:mm:ss.SSSXXX, UTC} [%X{myProp}] %-5level %logger{0}.%M\(%line\) - %msg%n
With MDC, we get these logs. Note the hash after the timestamp in each of the logs. Yes, this looks scalable.
2020-04-09T15:29:53.910Z [0b644eacd273d4c0] DEBUG MyLogger.doFilterInternal(45) - POST HTTP/1.1 /users/settings/save 2020-04-09T15:29:53.922Z [0b644eacd273d4c0] INFO MyService.performAction(181) - Try save user setting 2020-04-09T15:29:53.951Z [0b644eacd273d4c0] DEBUG MyInterceptor.log(27) - --> GET http://www.example.com/save/user?id=983 2020-04-09T15:29:53.990Z [3ecc5246ce0dc675] DEBUG MyLogger.doFilterInternal(45) - POST HTTP/1.1 /users/settings/save 2020-04-09T15:29:54.009Z [3ecc5246ce0dc675] INFO MyService.performAction(181) - Try save user setting with id: 983 2020-04-09T15:29:54.030Z [3ecc5246ce0dc675] DEBUG MyInterceptor.log(27) - --> GET http://www.example.com/save/user?id=983 2020-04-09T15:29:56.222Z [0b644eacd273d4c0] DEBUG MyInterceptor.log(31) - <-- 200 OK Saved 2020-04-09T15:29:56.235Z [0b644eacd273d4c0] INFO MyService.performAction(201) - Saved user setting 2020-04-09T15:29:56.472Z [3ecc5246ce0dc675] DEBUG MyInterceptor.log(31) - <-- 200 OK Saved 2020-04-09T15:29:56.481Z [3ecc5246ce0dc675] INFO MyService.performAction(201) - Saved user setting
Note that there is a unique identifier added to the logs, which identifies the log traces that are generated from the same request. And it's much better when we put the user identifier in the MDC context too. Now we have contextual information even in the logs from "MyLogger" and "MyInterceptor".
2020-04-09T15:29:53.910Z [user=1832, tag=0b644eacd273d4c0] DEBUG MyLogger.doFilterInternal(45) - POST HTTP/1.1 /users/settings/save 2020-04-09T15:29:53.922Z [user=1832, tag=0b644eacd273d4c0] INFO MyService.performAction(181) - Try save user setting 2020-04-09T15:29:53.951Z [user=1832, tag=0b644eacd273d4c0] DEBUG MyInterceptor.log(27) - --> GET http://www.example.com/save/user?id=1832 2020-04-09T15:29:53.990Z [user=983, tag=3ecc5246ce0dc675] DEBUG MyLogger.doFilterInternal(45) - POST HTTP/1.1 /users/settings/save 2020-04-09T15:29:54.009Z [user=983, tag=3ecc5246ce0dc675] INFO MyService.performAction(181) - Try save user setting 2020-04-09T15:29:54.030Z [user=983, tag=3ecc5246ce0dc675] DEBUG MyInterceptor.log(27) - --> GET http://www.example.com/save/user?id=983 2020-04-09T15:29:56.222Z [user=1832, tag=0b644eacd273d4c0] DEBUG MyInterceptor.log(31) - <-- 200 OK Saved 2020-04-09T15:29:56.235Z [user=1832, tag=0b644eacd273d4c0] INFO MyService.performAction(201) - Saved user setting 2020-04-09T15:29:56.472Z [user=983, tag=3ecc5246ce0dc675] DEBUG MyInterceptor.log(31) - <-- 200 OK Saved 2020-04-09T15:29:56.481Z [user=983, tag=3ecc5246ce0dc675] INFO MyService.performAction(201) - Saved user setting
A few things to note:
- Logs can be enriched with information regardless of where the actual logging occurred. You needn't pass around all the contextual information (like the "user" data in the above example).
- MDC works well in concurrent backend systems too. If you add a property to MDC from a parent Java thread, the MDC properties are inherited by all the threads that are spawned from the parent thread. You can think of MDC as a ThreadLocal variable that is not shared across multiple threads or an InheritableThreadLocal variable, which is inherited by the child threads.
- When dealing with microservices, tracing the logs and monitoring them is complex and vital at the same time. If you are writing services with Spring Boot, you can use Spring Cloud Sleuth, which automatically injects a unique id to a single request or job (called trace-id). A trace id can be split into multiple "spans" if needed. Sleuth has the option to integrate with aggregators like Zipkin.
Now let’s take a complicated concurrent system using Spring Batch framework and check if MDC works well there.
MDC in a Spring Batch Application
We have a small Spring Batch program that runs in a web application. The object of the program is to process a large sequence of documents from Mongo database and extract meaningful data in the shortest time possible and eventually save the inferences back to the Mongo database. We had a simple batch processing system set up for this.
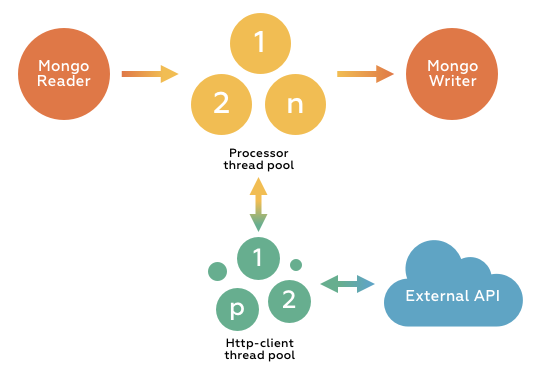
In our case, the batch job is a multi-threaded program and consists of a single step (which again is multi-threaded). In this step, we have a reader, a processor and a writer. The reader takes an input, the processor processes it, and the writer handles the output. The processor is also a multi-threaded program. So that's how it's been set up.
So in org.springframework.batch.core.configuration.annotation.BatchJobConfigurer we configured a custom JobLauncher. Here, we populated the context for the whole job, which would be available across the step threads, reader, processor threads, writer and the various job listeners and even the HTTP interceptors:
public JobLauncher getJobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher() {
@Override
public JobExecution run(Job job, JobParameters jobParameters)
throws JobParametersInvalidException, JobExecutionAlreadyRunningException,
JobRestartException, JobInstanceAlreadyCompleteException {
MDC.put("user", jobParameters.getString("username"));
MDC.put("#job", jobParameters.getString("jobId");
return super.run(job, jobParameters);
}
};
jobLauncher.setJobRepository(getJobRepository());
jobLauncher.setTaskExecutor(new SimpleAsyncTaskExecutor());
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
This had to work but it didn't. We were baffled. It took us a while to realize what was happening here. The multi-threading here is a Spring-flavored java.util.concurrent.ThreadPoolExecutor basically based on Java's Executor framework. The Executor framework reduces the overhead of creating threads by reusing a "thread-pool" and executing tasks on them. Because of this, the MDC context would not be inherited and so we have to do that explicitly. The solution was to use a TaskDecorator that copies the MDC context to the current Runnable task:
public class ContextAwareExecutorDecorator implements Executor, TaskExecutor {
private final Executor executor;
public ContextAwareExecutorDecorator(Executor executor) {
this.executor = executor;
}
public void execute(Runnable task) {
final Map<String, String> callerContextCopy = MDC.getCopyOfContextMap();
executor.execute(() -> {
MDC.clear();
if (callerContextCopy != null) {
MDC.setContextMap(callerContextCopy);
}
task.run();
MDC.clear();
});
}
}
And apply the Decorator task around the SimpleAsyncTaskExecutor:
public JobLauncher getJobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher() {
@Override
public JobExecution run(Job job, JobParameters jobParameters)
throws JobParametersInvalidException, JobExecutionAlreadyRunningException,
JobRestartException, JobInstanceAlreadyCompleteException {
MDC.put("user", jobParameters.getString("username"));
MDC.put("#job", jobParameters.getString("job");
return super.run(job, jobParameters);
}
};
jobLauncher.setJobRepository(getJobRepository());
jobLauncher.setTaskExecutor(new ContextAwareExecutorDecorator(new SimpleAsyncTaskExecutor()));
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
Now the logs are more readable with all the context data when we run our Spring Batch program:
10:18:00.515 [user=varun, #job=cb7e83f9] INFO o.s.b.c.l.support.SimpleJobLauncher - Job: [FlowJob: [name=myJob]] launched with the following parameters: [{date=1586666880222, totalRecords=5, prop1=value1, prop2=value2}]
10:18:00.547 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyJobExecutionListener - Starting batch job now...
10:18:00.737 [user=varun, #job=cb7e83f9] INFO o.s.batch.core.job.SimpleStepHandler - Executing step: [myStepSecured]
10:18:01.543 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#1] Starting process...
10:18:01.560 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#2] Starting process...
10:18:01.673 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#4] Starting process...
10:18:01.673 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#3] Starting process...
10:18:01.674 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#5] Starting process...
10:18:02.285 [user=varun, #job=cb7e83f9] INFO okhttp3.OkHttpClient - [#2] --> POST http://www.example.com/action
10:18:02.285 [user=varun, #job=cb7e83f9] INFO okhttp3.OkHttpClient - [#4] --> POST http://www.example.com/action
10:18:02.285 [user=varun, #job=cb7e83f9] INFO okhttp3.OkHttpClient - [#1] --> POST http://www.example.com/action
10:18:02.285 [user=varun, #job=cb7e83f9] INFO okhttp3.OkHttpClient - [#5] --> POST http://www.example.com/action
10:18:02.285 [user=varun, #job=cb7e83f9] INFO okhttp3.OkHttpClient - [#3] --> POST http://www.example.com/action
10:18:04.080 [user=varun, #job=34c52ea8] INFO o.s.b.c.l.support.SimpleJobLauncher - Job: [FlowJob: [name=myJob]] launched with the following parameters: [{date=1586666880222, totalRecords=5, prop1=value1, prop2=value2}]
10:18:04.111 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyJobExecutionListener - Starting batch job now...
10:18:04.143 [user=varun, #job=34c52ea8] INFO o.s.batch.core.job.SimpleStepHandler - Executing step: [myStepSecured]
10:18:04.209 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#1] Starting process...
10:18:04.211 [user=varun, #job=34c52ea8] INFO okhttp3.OkHttpClient - [#1] --> POST http://www.example.com/action
10:18:04.221 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#2] Starting process...
10:18:04.222 [user=varun, #job=34c52ea8] INFO okhttp3.OkHttpClient - [#2] --> POST http://www.example.com/action
10:18:04.222 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#3] Starting process...
10:18:04.223 [user=varun, #job=34c52ea8] INFO okhttp3.OkHttpClient - [#3] --> POST http://www.example.com/action
10:18:05.612 [user=varun, #job=cb7e83f9] INFO okhttp3.OkHttpClient - [#4] <-- 200 OK http://www.example.com/action (3320ms)
10:18:05.634 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#4] Received response in 4s
10:18:05.653 [user=varun, #job=cb7e83f9] INFO okhttp3.OkHttpClient - [#2] <-- 200 OK http://www.example.com/action (3360ms)
10:18:05.665 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#2] Received response in 4s
10:18:05.706 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#2] Winding up...
10:18:05.706 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#4] Starting process...
10:18:05.708 [user=varun, #job=34c52ea8] INFO okhttp3.OkHttpClient - [#4] --> POST http://www.example.com/action
10:18:05.765 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#4] Winding up...
10:18:05.767 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#5] Starting process...
10:18:05.769 [user=varun, #job=34c52ea8] INFO okhttp3.OkHttpClient - [#5] --> POST http://www.example.com/action
10:18:05.784 [user=varun, #job=cb7e83f9] INFO okhttp3.OkHttpClient - [#3] <-- 200 OK http://www.example.com/action (3493ms)
10:18:05.803 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#3] Received response in 4s
10:18:05.817 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#3] Winding up...
10:18:06.624 [user=varun, #job=34c52ea8] INFO okhttp3.OkHttpClient - [#1] <-- 200 OK http://www.example.com/action (2411ms)
10:18:06.645 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#1] Received response in 2s
10:18:06.656 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#1] Winding up...
10:18:06.710 [user=varun, #job=cb7e83f9] INFO okhttp3.OkHttpClient - [#1] <-- 200 OK http://www.example.com/action (4419ms)
10:18:06.743 [user=varun, #job=cb7e83f9] INFO okhttp3.OkHttpClient - [#5] <-- 200 OK http://www.example.com/action (4452ms)
10:18:06.775 [user=varun, #job=34c52ea8] INFO okhttp3.OkHttpClient - [#4] <-- 200 OK http://www.example.com/action (1063ms)
10:18:06.778 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#4] Received response from in 1s
10:18:06.789 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#4] Winding up...
10:18:06.959 [user=varun, #job=34c52ea8] INFO okhttp3.OkHttpClient - [#5] <-- 200 OK http://www.example.com/action (1186ms)
10:18:06.964 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#5] Received response in 1s
10:18:06.977 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#5] Winding up...
10:18:07.001 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#1] Received response in 6s
10:18:07.011 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#5] Received response in 6s
10:18:07.023 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#1] Winding up...
10:18:07.025 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyItemProcessor - [#5] Winding up...
10:18:07.159 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyJobExecutionListener - [#] Job finished in 6s
10:18:07.159 [user=varun, #job=cb7e83f9] INFO c.m.a.batch.MyJobExecutionListener - [#] Latency due to service calls: 24s
10:18:07.307 [user=varun, #job=cb7e83f9] INFO o.s.b.c.l.support.SimpleJobLauncher - [#] Job: [FlowJob: [name=myJob]] completed with the following parameters: [{date=1586666880222, totalRecords=5, prop1=value1, prop2=value2}] and the following status: [COMPLETED]
10:18:07.744 [user=varun, #job=34c52ea8] INFO okhttp3.OkHttpClient - [#2] <-- 200 OK http://www.example.com/action (3521ms)
10:18:07.869 [user=varun, #job=34c52ea8] INFO okhttp3.OkHttpClient - [#3] <-- 200 OK http://www.example.com/action (3645ms)
10:18:08.013 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#2] Received response in 4s
10:18:08.037 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#2] Winding up...
10:18:08.138 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#3] Received response in 4s
10:18:08.160 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyItemProcessor - [#3] Winding up...
10:18:08.250 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyJobExecutionListener - Job finished in 4s
10:18:08.250 [user=varun, #job=34c52ea8] INFO c.m.a.batch.MyJobExecutionListener - Latency due to service calls: 15s
10:18:08.445 [user=varun, #job=34c52ea8] INFO o.s.b.c.l.support.SimpleJobLauncher - Job: [FlowJob: [name=myJob]] completed with the following parameters: [{date=1586666880222, totalRecords=5, prop1=value1, prop2=value2}] and the following status: [COMPLETED]
You can see how the idea of having the business context in the logging framework is useful for tracing the interactions with your program. You can distinguish interleaved log output from different sources and MDC is very useful here. While we saw an example of a Java-Spring system here, the idea of MDC has been around for some time in most languages.