

Research shows that children primarily learn languages by observing patterns in the words they hear. Computer scientists are taking a similar approach to train computers to process human language.
Computers cannot process words directly. Vector representations of words, known as embeddings, are used to teach machines to make sense of them. Vectors encapsulate the properties of words in them, such as semantics or relations between words. Embeddings can also contain syntactic information and can have similar vectors for various forms of words, such as, he, him, his, etc. To obtain these vectors, models are trained with large volumes of text and the embeddings are learned during the process.
This is an example of the GloVe embedding of the word “rain” (with an embedding vector size of 300).

Overview of Static Embeddings
Word embeddings can be broadly classified into two: static and dynamic. Static embeddings have only one embedding per word regardless of the context in which they appear. These embeddings will thus be a mix of the various meanings of the word. Dynamic contextual embeddings consider the whole sentence before generating the word embedding. This makes it possible to provide different embeddings for words such as “bank” when they occur in varying contexts such as “river bank” or “bank loan”.
Even with its limitations, static word embeddings have found widespread use in many NLP applications such as classification, POS tagging, sentiment analysis, etc. This section provides a high-level picture of some of the most popular static embeddings.
Word2vec
Word2vec is one of the first word embeddings to find widespread popularity. It gives impressive results on word analogy tasks, such as finding words similar to a query word in a document. It works by training a shallow neural net to either learn to predict a missing word given the surrounding words (CBOW method) or the surrounding words given a word as input (skip-gram). CBOW is suitable for small datasets while skip-gram is more suitable for larger datasets.
Global Vectors (GloVe)
GloVe embeddings are generated on the basis of co-occurrence of words over the entire training dataset. They encapsulate the probability of two words occurring together. They are optimized directly on the dataset so that the dot product of two word embeddings gives the log of the count of the co-occurrence of the two words.
For example, if the two words “mountain” and “river” occur in the context of each other, say 20 times within a window of 10 words in the dataset, then the generated embeddings will satisfy:
Vector(mountain) . Vector(river) = log(20)
fastText
fastText is an improvement over Word2vec and GloVe in that it can support out-of-vocabulary words. During its training, fastText splits each word into an n-gram of characters. Consider the word “petrol” with an n-gram length of 5. The fastText representation of this word will be <petr, petro, etrol, trol>. The fastText model then generates embeddings for each of these n-grams.
This model can make sense of parts of words and allow embeddings for suffixes and prefixes. Once the words have been represented using character n-grams, a skip-gram model is trained to learn the embeddings. fastText works well with rare words. So even if a word wasn’t seen during training, it can be broken down into n-grams to get its embeddings. In the above example, the learned n-gram “petro” can be used for generating embeddings for words such as “petrochemical” or “petroleum” even when the model has not seen them before. This should be especially useful for complex agglutinative languages such as Malayalam.
Challenges Specific to Malayalam Word Embeddings
Widely spoken languages such as English and Chinese have well-developed word embeddings. Malayalam is an exceptionally difficult language for generating word embeddings as most of the words can occur in different forms in a sentence. It is a highly inflectional and agglutinative language. As an example, take the word, നീലപ്പീലിക്കണ്ണും. It is made by agglutinating നീല + പീലി + കണ്ണ് + ഉം. A large number of variations are also possible for each word. For example, take the word പാലക്കാട്. A large number of words can be derived from it, such as പാലക്കാടിൻ്റെ. പാലക്കാടിലെ and so on by modifying the ending.
This makes it difficult for models like Word2vec since they cannot handle out-of-vocabulary words. Dravidian languages, including Malayalam, are morphologically very rich—there is a large number of possible inflections for each word. All this has the consequence of increasing the word vocabulary size and reduces the number of observed instances of a given token in a dataset. This adversely affects the quality of the generated word embeddings.
The first thing we had to do was to find a large enough collection of Malayalam text. Currently, many regional languages such as Malayalam have a relatively smaller online presence. We initially scraped the web using tools such as Beautiful Soup and Lucene. However, Malayalam language content was hard to come by and older archives were not publicly accessible in many of the news websites. Even Wikipedia had only limited resources in Malayalam.
So, we began exploring alternative avenues and came upon Common Crawl archives, which has crawl data for a large number of languages including Malayalam. Most of this data is obtained from news sites and blog posts periodically crawled over the last decade. Please check our previous blog post to learn more about how we extracted the Malayalam data from Common Crawl archives.
Evaluation of Word Embeddings
Once the word embeddings are trained, we need to have a way of knowing how good they are. So having a proper evaluation metric is important. Evaluation metrics can be broadly categorized into two: intrinsic and extrinsic.
- Intrinsic: This type of evaluation takes into account the intrinsic properties of words and their relation to each other to directly get a measure of the quality of the embeddings themselves. It is more intuitive and speeds up the whole process of building quality embeddings.
Some types of intrinsic evaluation tasks are :
- Word Similarity / Relatedness: In this task, a dataset containing word pairs and manual similarity judgments is created. Using the learned word embeddings, a similarity metric between each word pair is created, such as cosine similarity between the embeddings. The correlation between the manually judged similarity scores and the ones provided by the embeddings defines the embedding quality.
- Word Analogy: Given a pair of words (A, B) with a particular relationship and a word C of the same type as A, the word analogy task involves predicting the word D that holds the same relationship with C as B holds with A. This task utilizes the linear relationship between word embeddings to search for the missing word. Word analogy datasets can capture semantic as well as syntactic relationships depending on the tuples included in the query inventory.
For example: Given two related words, man and woman, the task will be to predict to which words a new word such as “King” would map to under the same relation. A good model will be able to predict the word “Queen”.This can be expressed algebraically as King - Man + Woman = Queen. In other words, the vector difference between King and Queen should capture the concept of gender.
- Extrinsic: This type of evaluation measures the utility of the embeddings in another downstream NLP application like sentiment analysis, machine translation, named entity recognition, parts of speech tagging, news/article classification, etc.
We decided to evaluate using the intrinsic metrics as they tend to give a better picture of the overall quality of the models, not just for a specific application. Building evaluation datasets is a labor-intensive and time-consuming operation. To mitigate this problem, we decided to programmatically build an evaluation benchmark.
Our dataset consists of words from five categories (Languages, Animals, Places, Vegetables, Names). These categories were chosen as they appear in relatively distinct contexts in the training corpus we had. This helps the model to learn to more easily distinguish between each category. Each of these categories were then seeded with around 20 words that we picked randomly.
Then we formed triplets on the condition that wherever A and B are picked from the same category, C is chosen from a different one. In the examples shown below, words in columns A and B are picked from the languages category and the column C is made up of the words from the remaining categories such as names, places, etc. Status indicates that the row satisfies our condition.
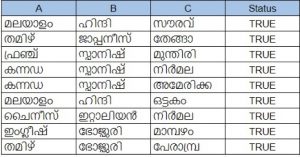
Using just 20 examples from each category, we were able to come up with around 1 lakh test cases. After a little experimentation with a smaller dataset, we decided to use it for evaluating models trained using the Common Crawl data.
Experiments and Results
Once we established the evaluation benchmark, we trained the different models with the Malayalam text obtained from the Common Crawl archives for the month of January. The results we obtained are summarized below:
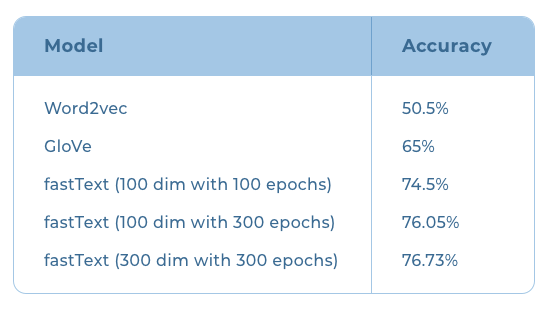
We began training with Word2vec and got an accuracy of 50.5%. Word2vec couldn’t handle many out-of-vocabulary words and hence offered low recall. GloVe embeddings couldn’t handle out-of-vocabulary words either but the accuracy improved slightly to 65% on our evaluation benchmark.
The next step was to try out models that could handle out-of-vocabulary words. This led us to fastText. Facebook had released a fastText model for Malayalam trained using the Malayalam text available from the Common Crawl archives. However, the data they used were scraped way back in 2018. When we ran our evaluation on this model, we got an accuracy of 78%.
Since the Common Crawl archives now had more data compared to the archives available in 2018, we decided to give training fastText a go. The same dataset obtained from the January 2020 Common Crawl archives was used for the training.
After the training, the models were evaluated on our custom evaluation metric. Training the fastText model for 100 epochs with an embedding size of 100 on this dataset, we got an accuracy of 74.5%. When we continued the training to 300 epochs, the accuracy improved to 76.05%.
We then increased the embedding dimension to 300 and retrained again using the same dataset for 300 epochs. This further increased our accuracy to 76.73%. Training after 300 epochs however,did not improve the results. At this point, we concluded that we need to improve the subword tokenization and text filtering to match or exceed the results of the Facebook trained fastText model—something we will have to ascertain through further exploration.