Research shows that children primarily learn languages by observing patterns in the words they hear. Computer scientists are taking a similar approach to train computers to process human language.


Share your requirements and we'll get back to you with how we can help.
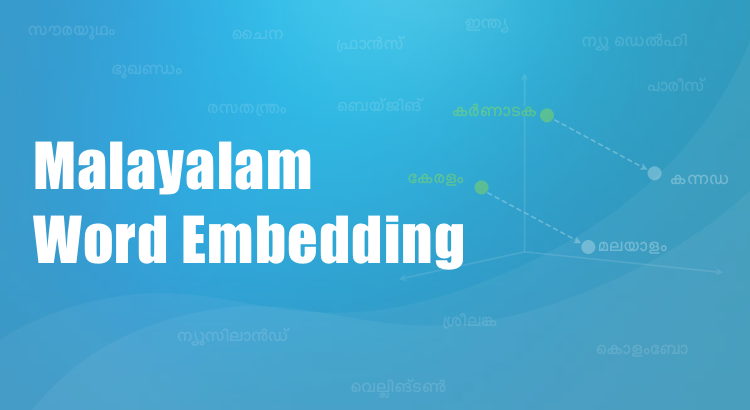
Research shows that children primarily learn languages by observing patterns in the words they hear. Computer scientists are taking a similar approach to train computers to process human language.