


In Part 1, we discussed how we extract text from invoices using PaddleOCR. Here we will outline the steps for retrieving relevant information from the extracted text using deep learning.
The invoices we had were dissimilar, so a template-based data extraction approach was out of the question. A Question-Answering (QA) Model was more appropriate in our case as the information we wanted to retrieve was present in the extracted text.
Question-Answering Model Selection
Question-Answering models are deep learning models that can retrieve answers to questions from a given context.
There are three QA variants:
- Extractive QA: This model extracts answers from a context, which could be a text, table, or HTML.
- Open Generative QA: This model generates answers in complete sentences based on the context. These answers may have additional words that were not present in the input text.
- Closed Generative QA: No context is provided. Answers are generated based on the dataset the model is trained on.
Of the three, Extractive QA was the apt one in our case since we had a context and answers had to be extracted from that context without any text changes.
QA Model from HuggingFace
In order to implement the QA model, we chose the transformers library from HuggingFace, a data science platform that provides state-of-the-art (SOTA) pre-trained models for different tasks in NLP and computer vision along with the tools to build, train, and deploy those models.
HuggingFace provides different variants of BERT, one of the most popular and widely used NLP models. BERT models consider the full context of a word by looking at the words that come before and after it, which is particularly useful when it comes to understanding the intent of the queries.
ALBERT Model
Initially, we used a pre-trained model of ALBERT, which is an upgraded version of BERT, a popular NLP model. The ALBERT model had an accuracy of more than 94% but extraction took more than 3 minutes on the CPU. Though it took less than 8 seconds on GPU, due to cost constraints, we decided to deploy the model on a CPU machine with 4GB RAM.

Intel / Dynamic TinyBERT
We looked for an alternative and found one in Dynamic TinyBERT, Intel's lightweight model optimized for CPU. TinyBERT is 7.5x smaller and 9.4x faster in inference compared to BERT.
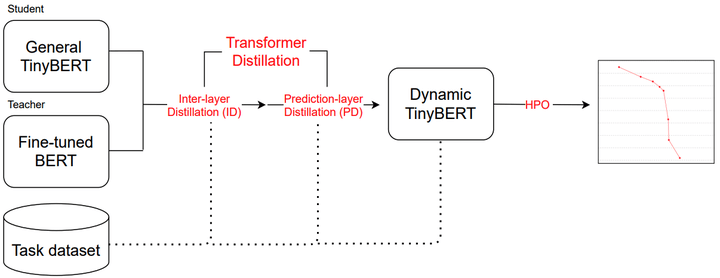
When we conducted a batch test on a set of invoices, the model performance improved from 240 seconds to 8 seconds.
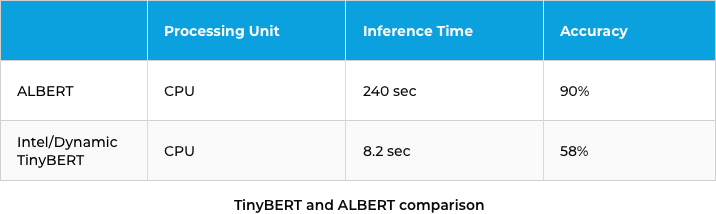
Though we got the output fairly quickly, accuracy was lacking compared to the ALBERT model. So we decided to fine-tune the model with our custom dataset.
Dataset Preparation
For fine tuning the QA model, we created our own custom dataset in SQuaD (Stanford Question Answering Dataset) format.
Sample SQuaD Format
{
"answers": {
"answer_start": [94, 87, 94, 94],
"text": ["10th and 11th centuries", "in the 10th and 11th centuries", "10th and 11th centuries", "10th and 11th centuries"]
},
"context": "\"The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave thei...",
"id": "56ddde6b9a695914005b9629",
"question": "When were the Normans in Normandy?",
"title": "Normans"
}
Data Annotation
In order to create our custom dataset in SQuAD format, we had to annotate the data (add labels and instructions to raw text) which will enable the machine to understand and recognize sentences and other textual data that are structured for meaning.
Among the many annotation tools, we chose to go with the open-source tool Label Studio due to its ease of use.
We had three outputs to extract: invoice number, invoice date, and invoice amount from each invoice. The questions we used were “What is the invoice number?”, “What is the invoice date?”, and “What is the invoice amount?”.
The below image shows how data is annotated in Label Studio.
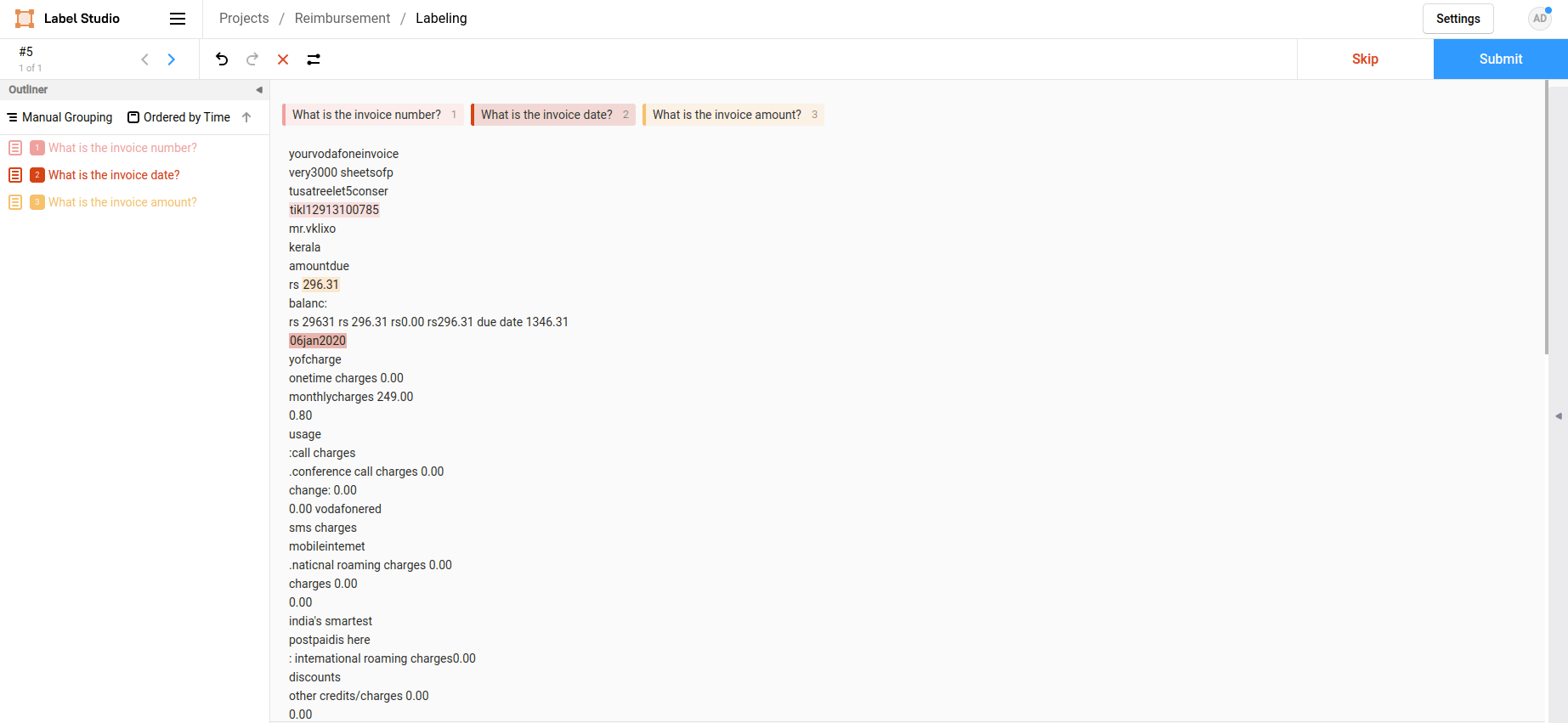
We annotated a dataset consisting of 200 fuel, mobile, and internet bills, which were in image and pdf formats. After annotating the bills, we exported the output in JSON (See sample below).
{
"Text": " bharat sanchar accountno 9038218739 invoiceno:sdckl0042250609\n nigam ltd d code date06/05/2020 invoice period\n bsn 01/04/2020to30/04/2020\n nbms/bms tariffplan:2gbbsnlcul\n postage pald in advancetaxinvolce\nvivinkv\n10/280a3.texasvillas\nnjaralloor telephoneno amount payable due date\nmillupadyjn\nizhakkambalam\nernakulam\n8356 kl 04842685287 403.00 21/05/2020\n paynow\n accountsummary\npreviousbalance paymentreceived adjustments\n gecruorue currentcharges totaldue amountpayable\n b406\n 399.34 400.00 2 0.00 403.41 402.75 403.00\n\n\n bharat sanchar accountno 9038218739 invoiceno:sdckl0042250609\n nigam ltd d code date06/05/2020 invoice period\n bsn 01/04/2020to30/04/2020\n nbms/bms tariffplan:2gbbsnlcul\n postage pald in advancetaxinvolce\nvivinkv\n10/280a3.texasvillas\nnjaralloor telephoneno amount payable due date\nmillupadyjn\nizhakkambalam\nernakulam\n8356 kl Annotation Screen Annotation Screen 04842685287 403.00 21/05/2020\n paynow\n accountsummary\npreviousbalance paymentreceived adjustments\n gecruorue currentcharges totaldue amountpayable\n b406\n 399.34 400.00 2 0.00 403.41 402.75 403.00\n\n",
"id": 1726,
"label": [
{
"start": 85,
"end": 100,
"text": "sdckl0042250609",
"labels": [
"What is the invoice number?"
]
},
{
"start": 166,
"end": 177,
"text": "06/05/2020 ",
"labels": [
"What is the invoice date?"
]
},
{
"start": 1085,
"end": 1091,
"text": "403.00",
"labels": [
"What is the total amount?"
]
]
}
Model Fine-Tuning and Inferencing
Our next step was to fine-tune the pre-trained TinyBERT model with the annotated data. We split the annotated data into train data and test data in a 7:3 ratio using Sklearn. We used the training script provided by simpletransformers library to fine-tune the model.
The fine-tuned model was loaded using the TransformerReader library. Then we fed the below questions and post-processed OCR output to the model for prediction.
- What is the processing fee? What is the total amount?
- What is the bill number? What is the invoice number?
- What is the date?
Predictions with the highest score were taken as the final answer for each question.
Post-Processing of Extracted answers
We cleansed the extracted answers and converted them to standard formats as per business requirements. This included:
- Changing the date into YYYY-MM-DD format.
- Removing currency symbols from the amount field.
- Converting amount in words to numerical.
- Rounding off the amount to the next integer value.
Output Analysis
We tested our framework using 50 files from each category, like mobile screenshots of PDFs (low-resolution images), fuel bills in both images and PDF formats, and Internet/mobile digital invoices.
The results are shown below.

The accuracy of the final output varied due to factors like:
- OCR accuracy (Quality and resolution of the input image)
- Size of the text content (Multi-page invoices)
- Noise in the text content (Presence of logos and images)
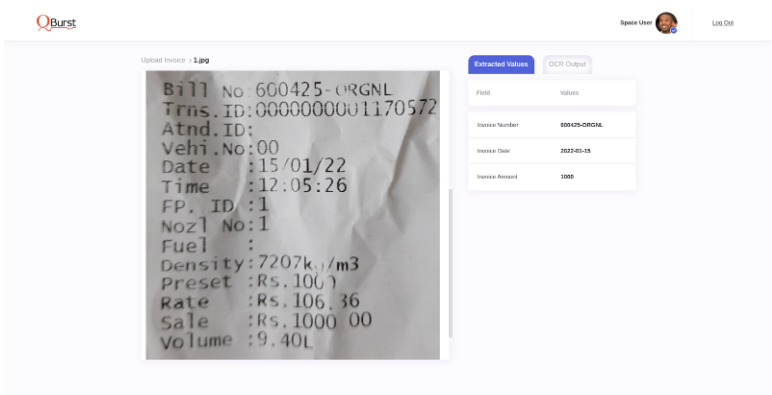
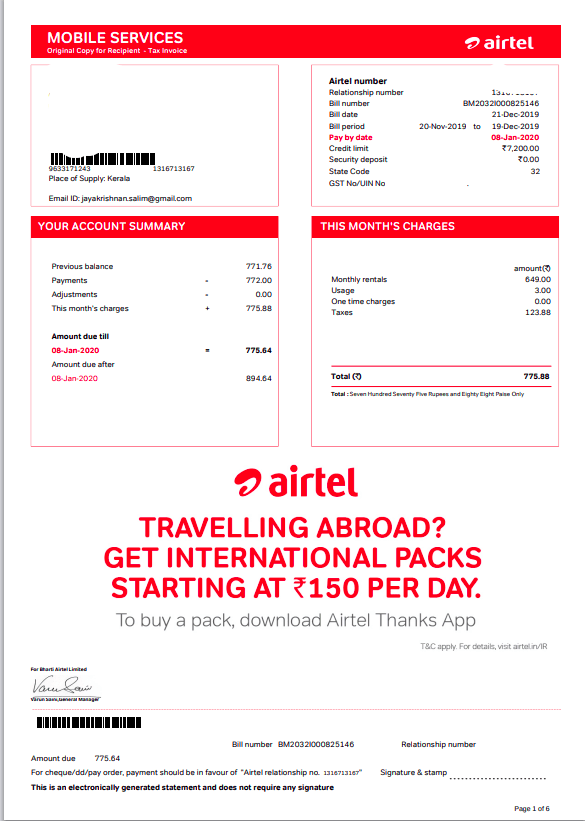
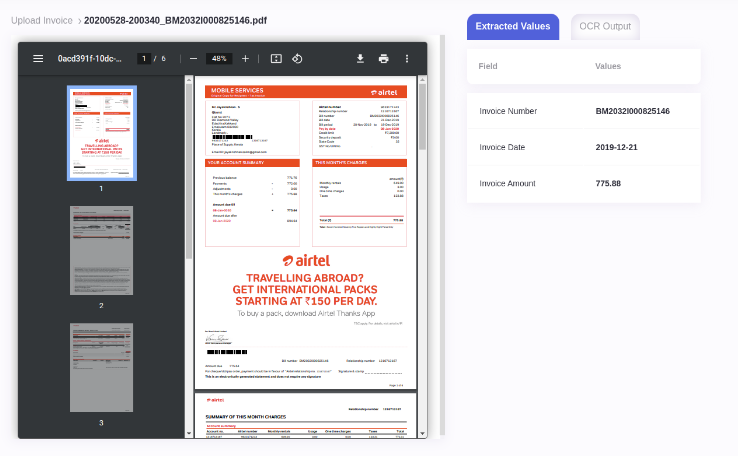
Sample Outputs from Intelligent Invoice Processing framework

JSON Output
{
"Invoice Number": "600425-ORGNL",
"Invoice Date": "2022-01-15",
"Invoice Amount": 1000.0,
}
Business Benefit
The invoice processing system we implemented reduced the manual effort for the client’s accounts team by more than 70%. It is a generalized solution that can be easily leveraged for the extraction/verification of any other document by modifying the questions asked.
For example, using the same framework, PAN cards can be parsed as shown below.

JSON Input
{
"questions": {
"Name": [
"What is the name?"
],
"Date": [
"What is the date?"
],
"Number": [
"What is the account no?"
]
}
}
JSON Output
{
"Name": "rahul gupta",
"Date": "1974-11-23",
"Number": "abcde1234f"
}
The highlight of this framework is that it is built using open-source technologies without any third-party commercial APIs.
