


In Part 1, we explored the advantages of the cloud-portable approach. Simply put, it allows businesses to benefit from cloud-native services while maintaining the flexibility to switch environments effortlessly.
My earlier post also offered a glimpse of the cloud-portable solution we built for a client. Interestingly, cloud-portable was not our client's first choice; cloud-agnostic was. But by taking the cloud-portable approach, we were able to help them nail the best of both worlds.
Read on to find out why we chose this approach and how we implemented a cloud-portable solution.
Platform Requirements and Design Decisions
Here is a quick summary of the platform requirements laid down by our client:
- It should be easily deployable in Azure and GCP
- It should ingest 6 million requests in 20 minutes, process some complex business logic, and call a third-party API for every request
- The third-party API might not always be available, so the system should guarantee at-least-once delivery to the third party
- It should track user responses (another high-ingress scenario) for analytics and reporting purposes
- It should be cost-efficient, scalable, and maintainable
The components of choice in the client’s original client-agnostic approach were:
- Kafka as the ingress layer for handling heavy incoming throughput
- KEDA or KNative as serverless functions for event-driven scaling
- Cassandra as log storage for handling heavy write throughput
- RabbitMQ as the message broker for inter-service communication
- Redis cluster for caching
Building the system with these components was not going to be a problem.
The problem lay in the complex infrastructure setup, maintenance, and scaling up—not to mention the recurring maintenance costs. Despite being deployed in the cloud, the benefits offered by cloud-native services (such as ease of use, scalability, and streamlined development) would be out of our reach.
After many deliberations, we unanimously decided to adopt the cloud-portable approach, combining the advantages of cloud-native services while ensuring portability through custom abstractions layered on top of these services. After this, the choice of services changed from:
- Kafka to Azure EventHub / GCP PubSub
- Cassandra to Azure Table Storage / GCP BigTable
- KEDA/KNative to Azure Functions / GCP Cloud Functions
- RabbitMQ to Azure ServiceBus / GCP PubSub, etc.
The extra effort required to craft the abstraction layer was minimal compared to what the alternative approach would have required.
The reference architecture diagram in Azure and GCP is given below:
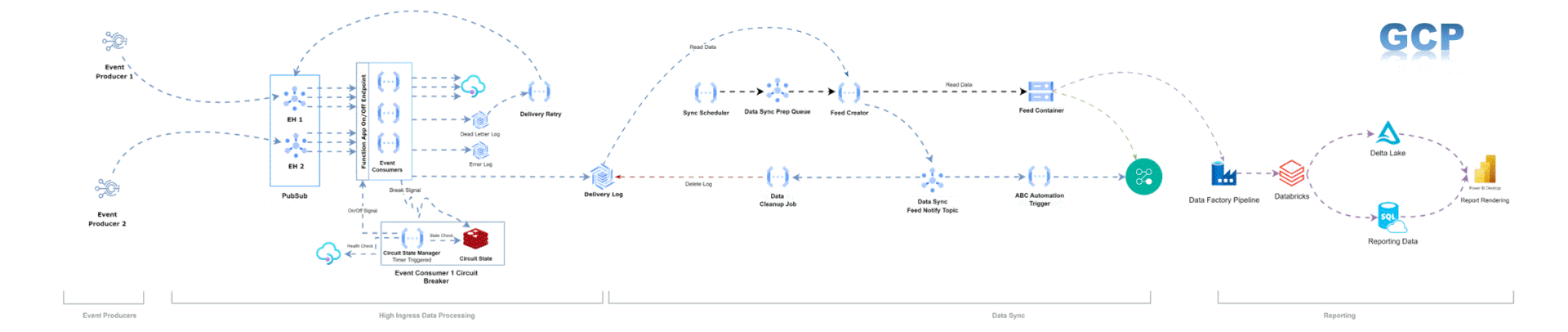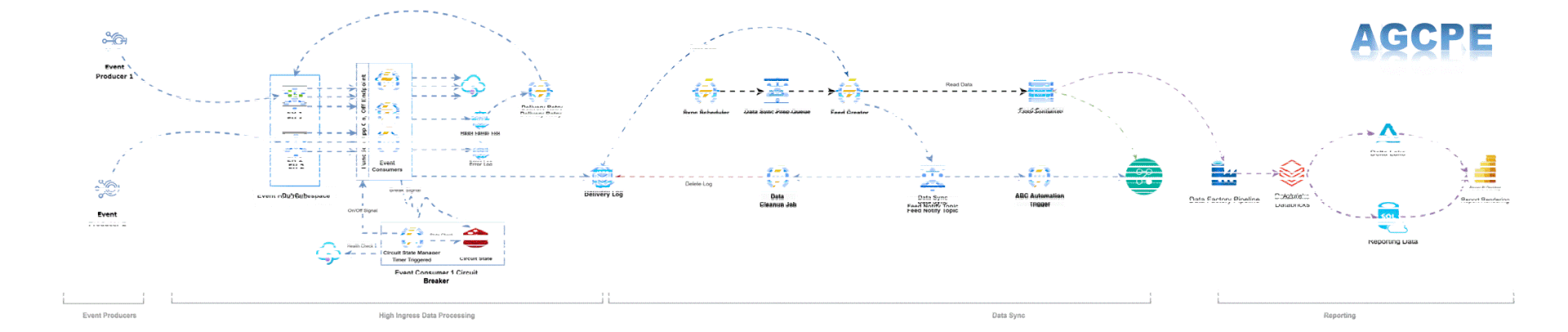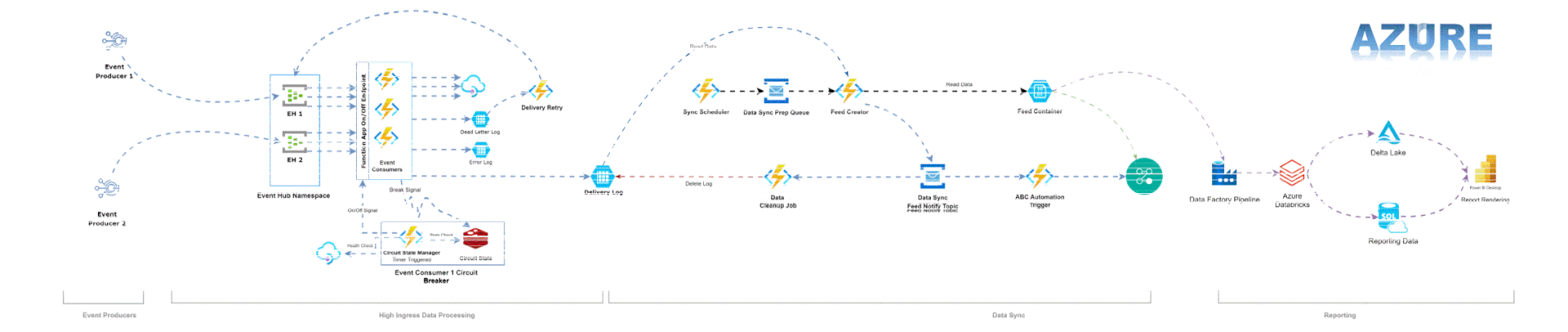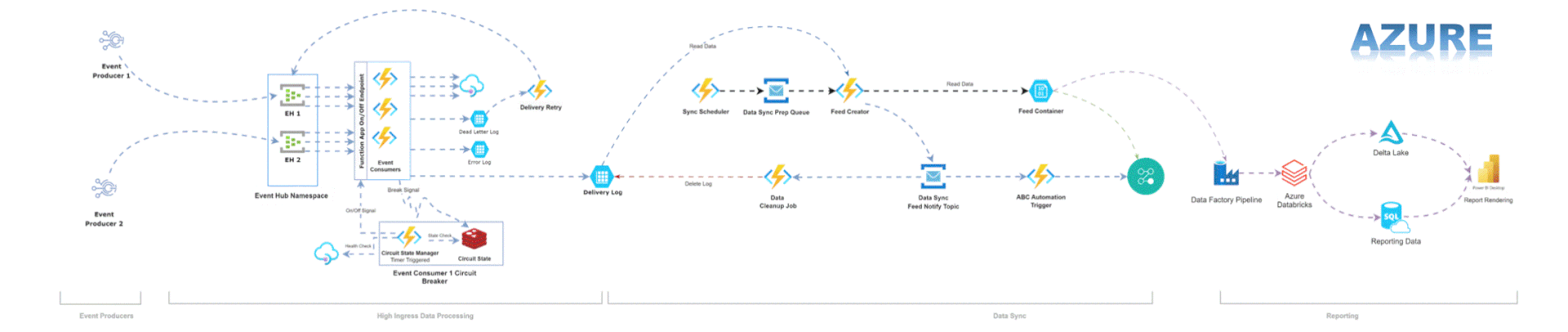
Abstraction: The Core of Cloud-Portable Solutions
At the core of a cloud-portable solution are abstractions. To make abstractions possible, the core business logic/code has to be independent—it should not interact with the cloud provider's SDK. It should operate solely on the abstraction layer, either off-the-shelf libraries or the custom libraries developed on top of the cloud-specific SDKs or implementations.
Let’s revisit the example in Part 1—the one involving a wide-column or key-value store—to illustrate the concept.
Our goal is to make our design flexible, making a smooth switch between Azure and GCP possible. Now, if our main code is too closely tied to one cloud provider's SDK, a maintenance challenge would ensue. Imagine dealing with two sets of code for Azure and GCP, each demanding separate updates, maintenance, and quality checks whenever we tweak the core code!
Here is the pseudo-code implementation of the above scenario. Please note that the pseudo-code is for explanation purposes only and is not guaranteed to compile or work. It considers InversifyJS as the IoC container.
The first step is to create the custom interface, preferably packaged and deployed as private packages. These packages, akin to npm packages for NodeJs or NuGet packages for .NET, encapsulate a generic abstraction tailored for storage, named "IColumnStore." This abstraction includes method signatures relevant to the storage functionality required.
icolumnstore.ts
export interface IColumnStore {
init(): Promise<void>;
insert(data: ISomeCustomDataInterface): Promise<void>;
findAll(query: IQueryOptions, useCustomQueryOnly?: boolean): Promise<IIteratorWrapper>;
delete(partitionKey: string, rowKey: string): Promise<void>;
update(data: IColumnStorageData, mode: UpdateModeEnum): Promise<void>;
upsert(data: IColumnStorageData, mode: UpdateModeEnum): Promise<void>;
}
Once the interface is ready, we can generate concrete implementations for Azure TableStorage and GCP BigTable as individual classes. These classes comply with the predefined method signatures of the "IColumnStore" interface and manage the storage functionalities of each cloud platform.
azuretablestorage.ts
import { injectable } from 'inversify';
import { IColumnStore } from './icolumnstore';
import {<required classes from azure storage sdk>} from '@azure/data-tables';
@injectable()
export class AzureTableStorage implements IColumnStore {
async init(): Promise<void> {
/* Logic to instantiate table storage client */
}
async insert(data: ISomeCustomDataInterface): Promise<void> {
console.log('Adding data to Azure Table Storage:', data);
}
/* remaining implementations of IColumnStore*/
}
gcpbigtable.ts
import { injectable } from 'inversify';
import { IColumnStore } from './icolumnstore';
import {<required classes from gcp bigtable sdk>} from '@google-cloud/bigtable';
@injectable()
export class GCPBigTable implements IColumnStore {
async init(): Promise<void> {
/* Logic to instantiate big table client */
}
async insert(data: ISomeCustomDataInterface): Promise<void> {
console.log('Adding data to GCP BigTable:', data);
}
/* remaining implementations of IColumnStore*/
}
Now that the concrete implementations for Azure and GCP are ready, let's explore how they can be integrated into the core business class.
Rather than relying directly on the concrete implementation of cloud storage, the core business code will work on top of the generic abstraction "IColumnStore" to avoid a direct dependency on specific cloud providers. To achieve this, the concrete implementation will be introduced into the business layer as a dependency, adhering to the Dependency Injection Principle. This method of injection ensures that the specific implementation for the chosen cloud provider is seamlessly integrated into the core business logic.
samplebusiness.ts
import { inject, injectable } from 'inversify';
import { IColumnStore } from './icolumnstore';
@injectable()
export class SampleBusiness {
private readonly columnStore: IColumnStore;
constructor(@inject('IColumnStore') columnStore: IColumnStore) {
this.columnStore = columnStore;
}
insertData(): void {
// Dummy data to be added
/* assuming this is the structure of ISomeCustomDataInterface */
const data = { key1: 'value1', key2: 'value2' };
/*
This SampleClass does not have any idea about the underlying cloud provider.
As far as this class is concerned, it just calls the "insert" function of the injected instance that
implements IColumnStore. It could be GCP BigTable or Azure Table Storage or any other storage and that depends on what got registered in the IoC container
*/
this.columnStore.insert(data);
}
}
The "insertData" method within the business class (in the above code snippet) remains agnostic to the underlying cloud storage details. It operates solely based on the implementation of the "IColumnStore" interface that was injected during the application's initialization. The Inversion of Control (IoC) container governs the injected instance, effectively determining whether the upload occurs in Azure storage or GCP storage.
As the final step, we inject the concrete class, choosing between Azure or GCP based on the specified requirement within the IoC setup file. The decision-making process for this injection can be facilitated by reading values from environment variables or dynamically determining the choice at runtime, perhaps from request headers. In our scenario, we simplified the configuration by relying on environment variables.
If the env variable was set to ‘AZURE’, then:
container.bind<IColumnStore>('IColumnStore').to(AzureTableStorage)
If it is GCP:
container.bind<IColumnStore>('IColumnStore').to(GCPBigTable)
The "SampleBusiness" remains unaware of the specific implementation of IColumnStore and whether the data will be stored in Azure Table Storage or GCP BigTable when it invokes the "insertData" function. The class only knows IColumnStore and its methods, eliminating any dependencies on cloud-specific SDKs or services.
Likewise, all other cloud-specific services can be wrapped with custom abstractions.
There are libraries that offer abstraction off-the-shelf. MassTransit is one of my favorites in the .NET world. It abstracts the underlying message broker and provides many cool features, so you don't have to do all the heavy lifting yourself.
In addition to custom abstractions, the Serverless framework played a crucial role in simplifying the development and deployment of Azure Functions and GCP Cloud Functions in our scenario.
Furthermore, we encountered a relational database implementation (not covered in this series) where our client’s sub-brands also had their individual database preferences, with some choosing SQL Server and others opting for MySQL. Through the use of Sequelize ORM (a powerful ORM), we were able to abstract the database layer and manage database schema migrations effortlessly.
Some Closing Thoughts on Cloud-Portable Strategy
Although some development effort is required to implement or deploy a cloud-portable solution, it is negligible compared to the recurring costs of managing extensive clusters on our own.
It is worth mentioning that not every enterprise client requires this level of flexibility. For some, the need to move to a different cloud provider might not even arise, and the platform might not be large enough to warrant concerns about vendor lock-in.
It is therefore crucial to make a distinction based on the client's specific needs and concerns. Some may truly benefit from a cloud-portable or cloud-agnostic solution, while others may not require the extra effort. By tailoring the implementation to each use case, we can ensure a successful cloud journey for our clients.
Check out Part 3 for a closer look at the challenges we encountered during the implementation and how we overcame them.
