


What's in this article:
- The workflow bottleneck that financial advisors struggle with.
- How we built an intelligent chat agent for financial advisors using Google ADK.
- Key engineering choices that improved the chat agent's response time.
- Techniques that made the agent production-ready.
The Advisor Workflow Problem
Financial advisors rely on multiple systems to manage client portfolios. A single client query requires jumping between the portfolio management system, CRM, trade logs, and real-time market feeds. Even simple questions like “Do I have spare cash to invest?” or “What’s my exposure?” often trigger a slow, error-prone search across several dashboards.
Agentic AI is fast becoming the answer to such tasks, as it cuts through fragmented data paths and brings relevant information in a single conversational interface.
This article describes the challenges involved in building an intelligent agent for financial advisors and the solutions we found.
The Data Layer Bottleneck
The first and most significant hurdle was the data layer.
We explored custom query generation (which is often a starting point for such applications), but the sheer density of the schema made it unfeasible. We were dealing with a massive ecosystem of tables where the potential for joins was countless. Fields across different tables often looked identical, and this confused the LLMs. Even with robust few-shot examples, the models could not reliably navigate the relationships between tables. It soon became clear that this approach lacks the necessary generalization for a production environment.
This made us re-evaluate our strategy.
Solving the Problem Through API Abstraction
The breakthrough came when we shifted focus from direct database interaction to the existing application APIs.
The decision to reuse the existing APIs gave us two clear advantages. Firstly, it simplified development by eliminating the need to build a separate backend layer. The decision to reuse the existing APIs gave us two clear advantages. Firstly, it simplified development by eliminating the need to build a separate backend layer. Secondly, it guaranteed data consistency because the chat agent and the advisor dashboard would from the same endpoints.
We structured the agent’s capabilities around a well-defined set of tools that enable the LLM to query enterprise APIs securely. To optimize performance, we also implemented a filtering layer to handle pagination and ensure the API responses remain within the LLM’s context window.
Examples of functions we used include:
- list_accounts(with filters): Identifies accounts and returns aggregate data. Filters can narrow results by state, available balance, or risk profile.
- get_position(stock_ticker): Retrieves total exposure to a specific stock, such as GOOG or AAPL.
- get_portfolio_health_summary(client_id, time_period): Calls multiple APIs to fetch performance data, compare asset allocation against the client's risk profile from the CRM, and generate a concise summary.
- get_transactions(client_id): Returns all trades and cash movements for a given client.
- get_activities(stock_ticker): Provides a list of corporate actions for a particular stock.
How We Designed the AI Agent
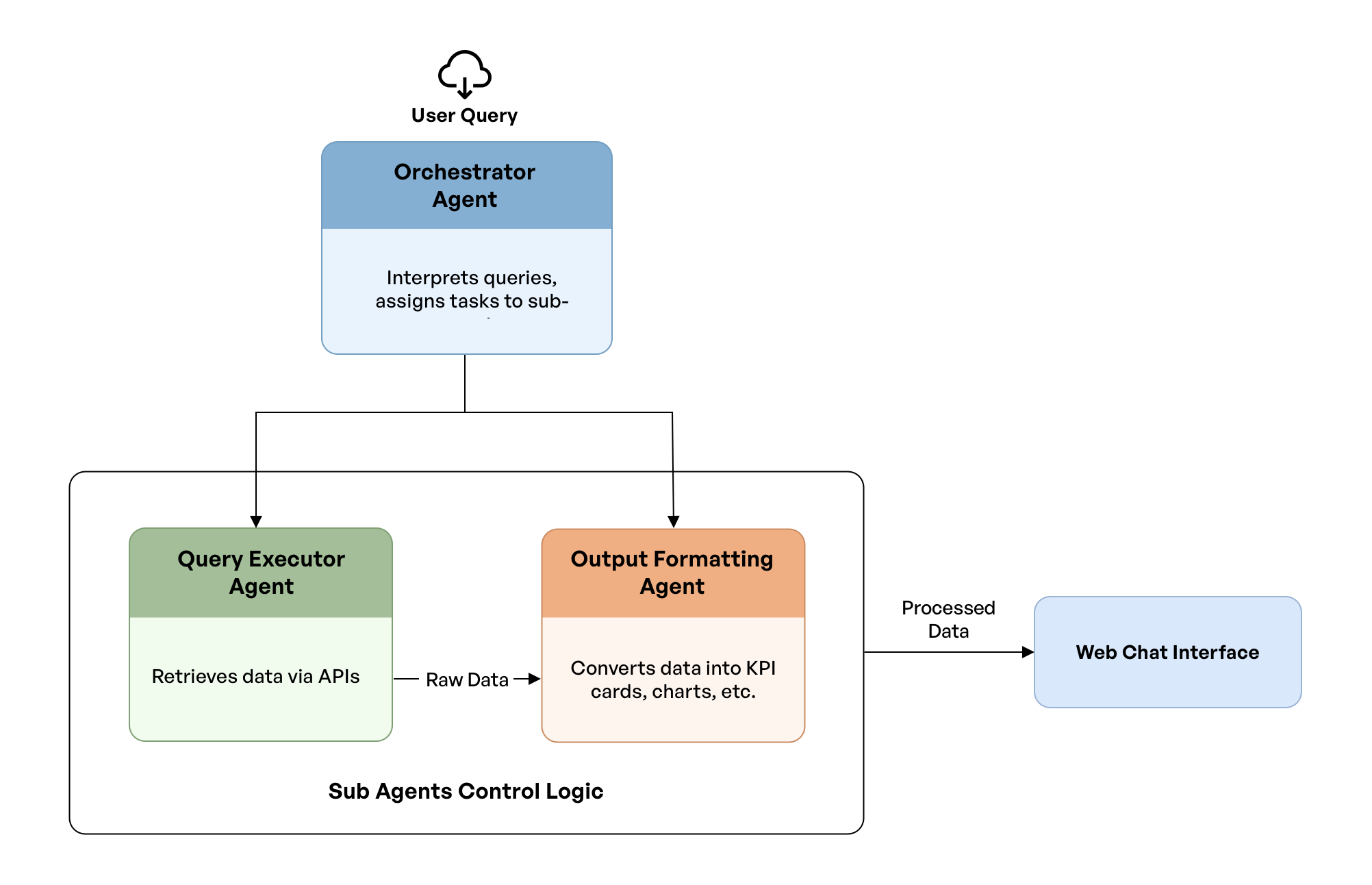
Rather than adopt a single, monolithic model, we went for a modular design using Google's Agent Development Kit (ADK).
At the heart of this design is the Orchestrator Agent, which acts as the central controller and decision-maker. Its primary responsibility is to interpret user queries, understand intent, and delegate work to the sub-agents, which are specialized, task-specific agents that operate with a narrow scope. This separation of concerns prevents context overflow and hallucination, and allows users to select different LLM models for different tasks.
We utilized two sub-agents:
- Output Formatting Agent: Once the raw data is retrieved, this agent transforms the data into standard formats such as tables, graphs, or cards. Since this is a deterministic task, we used Gemini Flash 2.5 with “thinking” disabled to maximize speed.
- Query Executor Agent: This agent handles all the data fetching. Because this requires complex reasoning, we used Google’s Gemini Flash 2.5 with "thinking" enabled.
This decoupled approach not only enhances maintainability but also enables advanced strategies. For example, the Orchestrator can preemptively start formatting and streaming a response via the Output Formatter as soon as the first tool calls are complete, rather than waiting for the entire execution cycle to finish.
We chose FastAPI over traditional frameworks like Django to meet our specific performance needs. FastAPI's native asynchronous architecture was essential for handling I/O-bound operations (such as calling multiple external APIs) without blocking, which is critical for maintaining low latency low during concurrent user sessions.
Further, FastAPI's unopinionated high-performance design gave us the architectural flexibility required for an evolving Agentic system. Its modern Python type hints ensure robust data validation and cleaner code without imposing the overhead of a monolithic framework. The combination of FastAPI with Uvicorn also provided the robust WebSocket support needed for real-time communication.
Engineering Real-Time Interaction
With the data access strategy in place, the next major challenge to overcome was latency. Initial tests showed response times in the tens of seconds, which is slow for a chat application. We adopted a systematic approach to bring these numbers down.
- Websocket Implementation and Session Management: For real-time communication, we utilized FastAPI WebSockets. To maintain conversational context across these socket connections, we relied on ADK’s built-in session management capabilities backed by a PostgreSQL database. This gave us a reliable and scalable way to track user interactions.
- Custom Agentic Loops: We designed custom agentic loops for granular control over execution flow and efficient task optimization. We also leveraged callbacks during tool calls, LLM invocations, and agent interactions to further extend functionality and enhance coordination between sub-agents.
- Managing Tool Overhead: For complex queries, the latency remained high: around 10 seconds for single tool calls and 15 seconds for queries requiring multiple tool calls. This was because every tool call requires two LLM calls: one to pick the right tool and another to process the result. Then, the final output formatting agent formats the results before passing them to the UI.
- Speculative Answer Generation: To further minimize the latency, we implemented a technique called speculative answer generation. As soon as the Query Executor receives raw data from a tool, the Output Formatting Agent begins transforming that data into UI components (tables, graphs) in the background while the Executor is still performing its final validation. By the time validation is complete, the formatted response is ready to serve. This effectively converts dead time into productive processing. This helped us bring down single tool call queries to 6 seconds and multi tool call flows to 10 seconds.
- Explicit Caching: We leveraged Explicit Caching to significantly speed up our agentic flows. This is how it works: The parts of the prompt that are reused across queries are precomputed so that only the dynamic part is processed during each turn. This led to significant savings in time and cost. The cache was initialized during application startup and periodically refreshed.
- Context Prefetching: Instead of forcing the agent to lose time waiting for a tool call just to look up basic metadata such as User ID, session details, or last login, this information is fetched via multithreaded API calls and injected directly into the initial prompt.
Optimizations to Make the System Production-Ready
To further enhance the user experience, we implemented other advanced techniques:
- Fast-Tracking Simple Interactions: We noticed that many user inputs are simple pleasantries that don’t require deep reasoning. We designed a quick-exit pathway that detects these interactions early and returns a programmed response immediately. This optimization bypassed the complex agent processing entirely, bringing response times for these cases down to 2.5 seconds and making the chat feel more organic.
- Security: Platform-level service tokens for tool access are fetched once and cached until expiry, removing repeated authentication overhead. Impersonation is used to enforce Row-Level Access Control (RLAC), ensuring the tool operates with the correct user context.
- Managing Perceived Latency: We also addressed the perceived wait time. Instead of a generic spinning loader, we implemented specific UI states. The agent displays active status messages (for example, "Fetching portfolio data...") to keep the user informed while the backend processes the request.
We considered using Gemini Live API to further reduce latency for simple scenarios. This gave a latency of 1 second for the LLM calls compared to 2-3 seconds for the Gemini Flash 2.5 models. However, the ability to discern between tools took a hit. As our solution involved a large number of tool calls, we decided to avoid the Live models.
Evaluation and Safety Guardrails
To ensure both quality and agility in our development process, we established a rigorous evaluation framework. This framework was instrumental for validating prompt modifications and enabling rapid prototyping.
For each change, we ran a suite of benchmarks to meticulously track the agent's behavior—analyzing the sequence of tool calls, the accuracy of their selection, and the latency at each step.
To assess the quality of the final output, we employed an LLM-based "judge" to score the relevance and correctness of the response. This two-pronged approach allowed us to streamline development, confidently iterate on our designs, and safeguard against any performance or quality regressions.
We used a strict system prompt to prevent the agent from giving financial advice and out-of-context answers. It was tuned to nudge advisors to make queries related to the financial domain only. The instructions were tuned to keep the agent strictly focused on data retrieval and financial analytics, ensuring it remains a compliant assistant.
Looking Ahead
With the help of the chat agent, financial advisors can now retrieve the information they need in seconds instead of the several minutes it once took to search, cross-reference, and validate data. The same architecture can be pushed even further by integrating low-latency models such as Gemini Live for time-critical interactions.
Any role that depends on fragmented systems, repetitive analysis, and high-stakes decision-making stands to benefit from intelligent agents. This project is one example of how AI agents can streamline work at scale, and the same model can support a wide range of scenarios across the financial ecosystem and beyond.
