


One of our clients in the banking sector recently came up with a request (or challenge, rather).
While it is true that digitalization has brought a world of difference to banking, we are still nowhere near paperless banking. Regulations require banks to collect different types of documents from customers at the time of onboarding and for various other services.
On an average, a single branch has to process at least hundreds of these documents on a daily basis. Automating this workflow would save the bank plenty of time and labor. The client wanted to build an Optical Character Recognition (OCR) solution that could be seamlessly integrated into the existing banking software.
This was, indeed, a perfect case for Robotic Process Automation (RPA). We took up the challenge and went for a proof of concept.
Challenges in Data Extraction
There were quite a few challenges for us to get past.
Data Privacy and Security
The documents customers submit at the bank contain a lot of personal details, which cannot be shared with a third party. Our client was not in favor of using cloud services but preferred an in-house solution for data extraction.
Data Integrity
The extracted data should match the data on the document. Even though the documents will be manually verified later, the application should always work with one hundred percent accuracy.
Document Quality
Getting good quality images was going to be a tough proposition. The documents are scanned using the scanner machine at the bank. There was a high chance for distortions like skewing, incorrect orientation, unwanted noise, and blurring in the scanned images.
Document Types
Besides Aaadhar and driver’s license, a variety of documents are collected at the bank. Some documents have data on two sides (see image below). The pattern, format, and position of data vary for each document type.

Document Versions
Any system we build has to support the changes in the structure of the documents as and when they are updated by the government. In other words, the system should be able to support multiple versions of each document at the same time.
Choosing the Technology Stack
Next came the question of choosing the right technologies. Our team had previously worked with Ruby on Rails, but for our current requirement, we decided to go ahead with Python due to developer community support for data science projects. Google Cloud Vision API would have been a good choice too, but the client did not want to involve third parties.
For data extraction, we considered different OCR solutions, both Open Source
Development Plan
Our work consisted of five steps:
- Image quality enhancement - Improve the quality of the images using image processing libraries
- Image segmentation - Separate different documents in a single scanned image
- Image classification - Classify segmented images into different groups
- Image orientation - Detect and correct image orientation
- Data extraction - Extract data in
required format
Image Quality Enhancement
This is the part where we had to
The quality of the images varied, depending on many factors:
- Configuration of the scanner like DPI, resolution, etc.
- Noises within the documents, like folding marks.
- Skewed position while scanning.
A few weeks later, the client gave us a few real samples under the strict condition that the data not be made public. Our worst fears regarding image quality proved to be true. None of the samples had the quality we wanted, making our work harder.
We spent weeks trying out different Image processing techniques and tools.
Since the color of the document is not an important property, we decided to use grayscale as the color space. Also, Tesseract gave better results with a binarized image than a grayscale image (Binarization is the process of converting a pixel to either black or white based on a threshold value; the result will be a black and white image.) Initially, the threshold value was hard-coded based on our observations of a few document samples. But those threshold values didn’t work well with low-quality images. OpenCV adaptive thresholding techniques helped to an extent to overcome this issue.
Original Image
The following is a sample image containing some random data.

Grayscale Image
Since the color of the image is not an important feature, it's better to convert the image from three color channels to one color channel, preferably grayscale.

Binarized Image
We can convert the grayscale image to a binarized image with which the OCR engine tends to perform well compared to either colored or grayscale images. Binarized image is just a black and white version of an image. The pixels are converted to either black or white based on a threshold value.

As you can see, some noises (small black dots) remain after binarization.
After noise removal
Noise removal techniques provided by the OpenCV helped us to get rid of such noises. When we noticed that some data was getting lost during the cleanup, we decided to keep noise removal to a minimum.

Sharpened Image
The pixels in noise-removed images may be arranged in a discontinued fashion at least in some areas. Such areas should be smoothened before feeding the image to the OCR engine.

The following image processing libraries got us through this crucial stage:
Image Segmentation
A single scanned image may contain more than one document. Each document must be separated before data extraction. This was done through image segmentation. Different features of the images like contour, edges, corners, histograms, etc., were analyzed to perform the segmentation. Since we were dealing with a known set of documents, the aspect ratio of each document was checked to see if it comes in the expected range of values. This step helped to avoid false areas.
Image before segmentation

Images after segmentation


Image Classification
Once the documents were separated, the next step was to classify them. We had trained a deep learning classifier to identify between Aadhaar card, driver’s license, voter’s ID card, and passport using state-of-the-art machine learning technologies.
Since we didn’t have enough data to train a classifier from scratch, we retrained an existing image classifier for our images (a process known as Transfer Learning). After trying different base models, we chose Inception v3 as the base model for our image classifier. We collected samples of each document type and created a data set and retrained Inception v3 model with this new dataset. This helped identify various input images by their type, that is, whether the image is that of Aadhar card or driver’s license or passport.
Before running classification, we checked the angle of inclination with the
Images before correcting skew


Images after correcting skew

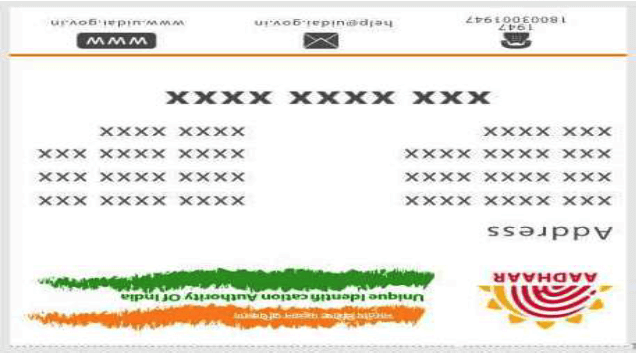
Image Orientation
The orientation of the images varies with the document type. The orientation depends on the dimensions of the document, that is, some documents have greater width compared to their height and vice versa.
To correct the orientation of the images, we tried several options like pattern matching and feature matching but none of them worked perfectly. Finally, we decided to bring in machine learning algorithms to identify the orientation. Multiple deep learning classifiers were trained for each document type to detect the orientation. Once the orientation was detected, the corresponding document was rotated at a proper angle using image processing techniques.
Image before correcting orientation
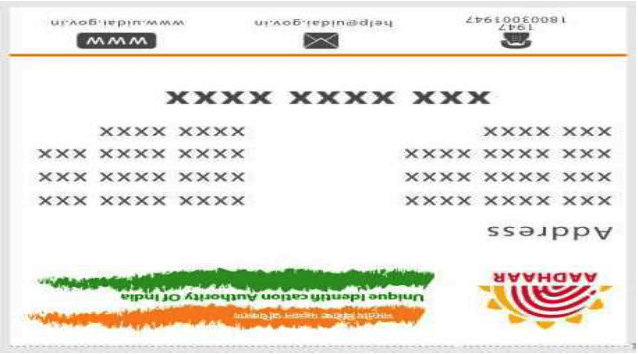
Image after correcting the orientation

Data Extraction
We now had better quality and categorized documents as input. The next step was to extract data from the documents using Tesseract. Tesseract can identify not only the characters in the image but also the positions of each character. This positional information is useful for detecting the data.
Data within the documents
Input Image

Data Detected by Tesseract
The following table shows the data detected Tesseract in tsv file format.
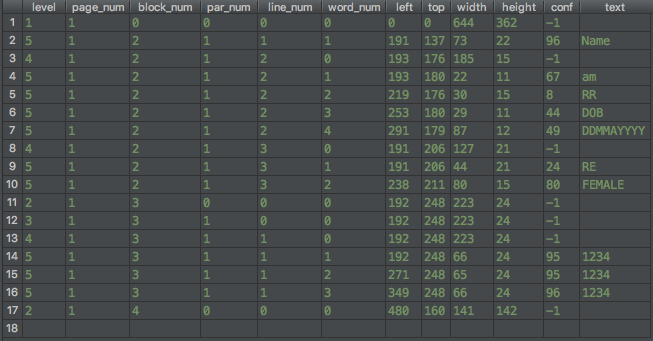
Tesseract detects a lot of information about the text in the document, but the following columns are particularly significant in our case:
- The ‘left’ column value, which indicates the position of text from the left border of the image.
- The ‘top’ column value, which indicates the position of text from the top border of the image.
- The ‘width’ column value, which indicates the width of the text.
- The ‘height’ column value, which indicates the height of the text.
- The ‘conf’ column value, which indicates the confidence score of the prediction.
Successful Delivery
We provided the OCR solution as an API as well as a web app with a very simple user interface. The code base was packaged as a docker container, which could be easily hosted on a server at the client location.
We observed that for the data extraction system to give good results the following preconditions had to be met:
- There should be no overlapping of documents.
- The images should have reasonable quality.
Having resolved the challenge posed by the client, we were given an even more challenging requirement—extracting data from handwritten forms. More on it in our next post!