


In the field of natural language processing (NLP), data is king. The more data you have, the better your results. Most new research is freely accessible these days and, thanks to the cloud, there is unlimited computing power at our disposal. What keeps an NLP researcher from achieving state-of-the-art results despite this is the lack of good data.
Common Crawl
Normally, to get large amounts of data, you would have to make use of scrapers such as Lucene or Beautiful Soup. Even then, it is a time-consuming process and a lot of tuning is required to get good results.
This is where Common Crawl, the nonprofit, comes into the picture. It provides web crawl data free of cost to the public. Anyone who wants to dabble in advanced NLP technologies can make use of this data.
Common Crawl archives have petabytes of raw HTML data collected since the beginning of the last decade. Usually, crawls are made each month and are made available by the code YYYY-WW, where Y stands for year and W for week. The latest such crawl is labeled 2020-05, which means the crawl was done on the 5th week of 2020.
Common Crawl data is stored on Amazon Web Services’ Public Data Sets and on multiple academic cloud platforms.
Size of the Dataset
One challenge with the dataset is its size. Downloading terabytes of monthly crawl data seems like a bummer, which might make users consider crawling their own data. But why reinvent the wheel?
Common Crawl provides an index of its records, such as the languages each record contains and the domains. Using this information, we can extract relevant records for any NLP application.
On the Common Crawl website, we can see the percentage of records available for each language in the archives.
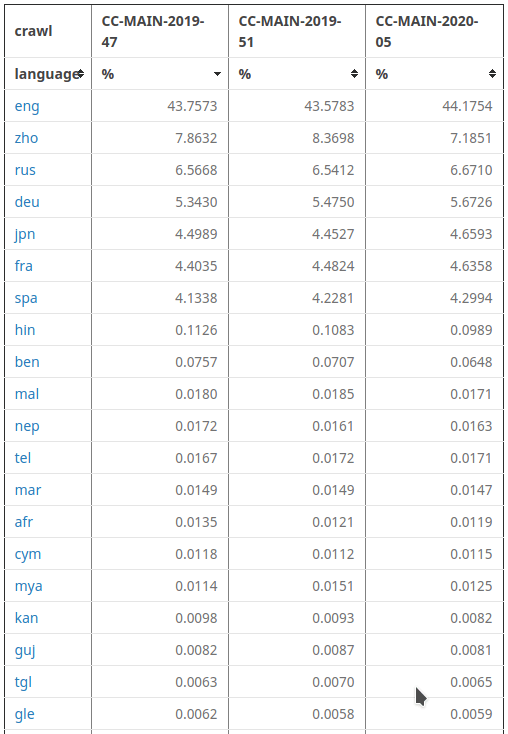
Malayalam (mal) makes up around 0.017% of the whole data in 2020-05. This might seem like an insignificant number at first, but when you take into account the size of the dataset, it amounts to around 50 GB of raw HTML records.
Addressing the Magnitude of Common Crawl Data
We decided to get our hands on the Common Crawl data ourselves and see how much effort downloading Malayalam records required. We were amazed by the sheer magnitude of data. We initially set out to download around 300 TB of HTML data and then filter out the Malayalam content. The cc index came to our rescue. We filtered out records that contained Malayalam as their primary or secondary language. There was an SQL index that could be queried through AWS Athena. The steps to do so are available in our repo.
After running the Athena query, we got the offsets of the records in the WARC (Web Archive) files in S3. Then, by running a Spark job, we extracted only the Malayalam records and saved them in S3. We utilized an AWS EMR cluster for the job.
You can also use our shell script to extract the WARC files into your own S3, which is also made available in our Repo.
Once we had the WARC files, the next challenge was to extract the Malayalam content from them. So we wrote a custom script to filter out only Malayalam paragraphs. This seemed to work pretty well.
We got the Unicode character range of Malayalam text and then scanned the input text character by character. When we encountered digits or special characters like dots or parentheses or quotes in a Malayalam block, we included them. Else, they were excluded. For this, we made use of a queue to track the characters. This was an experimental approach (there might be additional processing that could make this better). We also made use of the selectolax library to extract the parsed HTML text from the raw HTML.
The Common Crawl archive for CC-MAIN-2020-05 has 0.017% of Malayalam records, which means around 50 GB of Malayalam HTML raw data could be found in the 300 TB Common crawl corpus for a month. After a bit of preprocessing to remove the HTML and JavaScript, we were able to extract around 8 GB raw Malayalam text from each month’s Common Crawl data. In this manner, we were able to extract the Malayalam records from Common Crawl for Oct’19, Nov’19, Dec’19, Jan’20, and Feb’20. This cleaned dataset is available here.
Some examples of the cleaned data are shown below.

Common Crawl releases a new crawl each month. Using the script in our GitHub repo, you can collect more and more data. Our script also takes care of duplicate URLs and thus prevents the accumulation of redundant data.
Here’s to hoping this effort will invigorate further open research in Malayalam NLP and result in state-of-the-art models using Bert, GPT, and ULMFiT. Do keep in mind that Common Crawl does not take any responsibility for licensing issues and their code is available under the MIT license.
