

In our previous blog post, we discussed how we extracted printed text from ID cards to speed up application processing in banks. Here we look at how we extracted handwriting from KYC forms.
Many banks still continue to keep a signed hard copy of customer data for legal purposes even though it is easier to digitize the application process. They also collect hard copies for many transactions.
A typical account opening form with handwritten data looks like this:
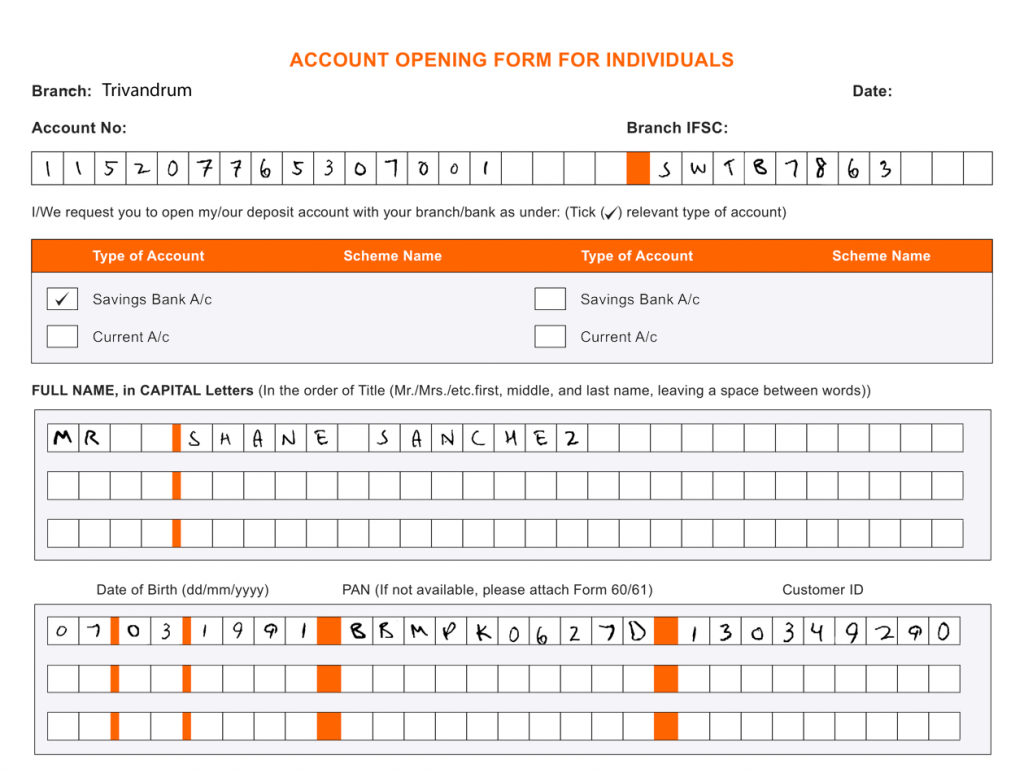
Our banking client collects thousands of such user-filled application forms. They wanted a system that would extract relevant details like first name, last name, Date of Birth, etc., from each form. High accuracy was required so that the system could operate with minimum human intervention. The system would collect documents from a remote FTP server as and when they came in. The extracted data would be displayed on the interface for admins to validate.
We set out to build a system that can recognize handwritten text with an accuracy of over 90% so that it could be used with minimal admin oversight. We will go into each component of the solution in detail below.
Technology stack
We used Django Framework to build our application. Celery task manager and Redis queues were used to handle the object detection workload. OpenCV and Tesseract were used for preprocessing and segmentation of character boxes. Tensorflow was used for powering the classifier.
Preprocessing
The first step was to clean up the input image. For this, we made use of techniques such as noise removal, skew correction, and thresholding. These techniques were all implemented using the openCV image processing library.
The application forms were scanned using a standard scanner in the DPI range of 200 to 300 and converted to either JPEG or TIFF formats. Many images were blurred, tilted, or had other types of deformities. Addressing the varying quality of forms was a major challenge for us. Some of the steps we took to improve the quality of the image are listed below.
- Noise removal cleared the minor spots caused by dust, accidental pen impressions, etc.
- Skew correction was done to fix the tilted images. We detected the straight lines in the images and used them to align the forms.
- Thresholding was done to binarize the images, that is, convert the images to binary format as the machine learning models perform better if the input is binary.
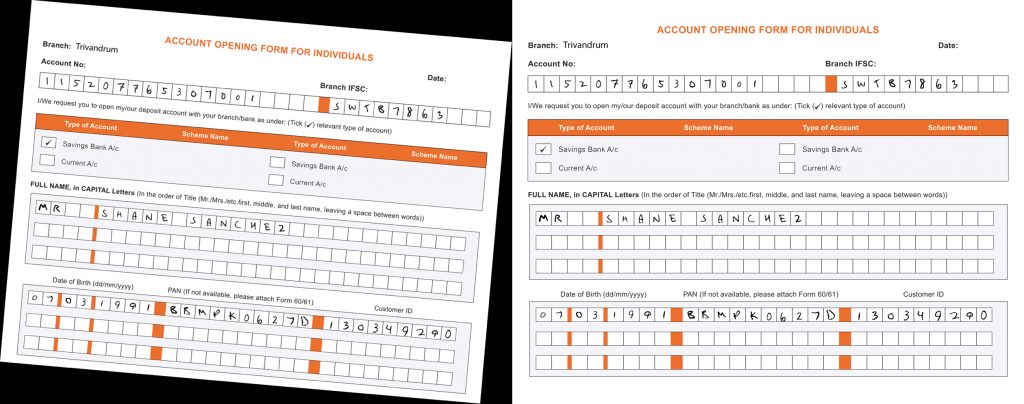
Segmentation
Segmentation is the process of extracting relevant information from the images in the form of bounding boxes. We used both OpenCV contour detection technique and Tesseract OCR for this.
Contour detection helps to detect continuous curves along the boundaries of images that have the same color or intensity and to locate the rectangular sections that are to be cropped. Before finding the contours, we also applied Canny edge detection to bring out the edges.
The preprocessed images were fed to the object detection neural net to detect the outermost boxes of the forms. Once we had the outer boxes, the images were fed to the Contour Detection module to obtain the name fields, which were finally cropped out from the forms.
In the Tesseract approach to segmentation, we employed a suite of OCR tools to detect the printed text in the forms. The model first prints out the entire text in the image. We then searched for the text corresponding to each text field. Once we found this landmark text, we got its pixel position in the images. We were able to guess the positions of the filled boxes using this pixel information. Please refer to our previous blog post for more details of this process.


Once we identified the outer sections, we continued to use the Contour approach to detect the inner boxes and segment the characters individually. These character images were then passed on to the machine learning model for recognition after resizing to 128 * 128.
Character Recognition
Character recognition is not as simple as it seems. Some of the fields have digits, some have alphabets, and some, such as addresses, contain both alphabets and digits.

We had to choose between a single character recognition model or three separate models. After a lot of experimentation, we found that better results could be obtained if we have different models for each type. This would prevent misclassification of characters such as ‘I’ and `1’. So we trained three separate models, each specialized in its own kind of data.
The input was the cropped image of a character. We choose grayscale images of dimension 128 * 128. What we expected was a prediction of the character. It may be a number or an alphabet, lower case, or upper case.
Conventional techniques don’t provide high accuracy as there are far too many ways in which a character can be written that can’t always be captured in code. So, we needed a method by which approximate shapes could be mapped to the closest cluster. This is where Deep Learning comes in.
We chose neural networks as they can handle a wide variety of handwriting styles. As a field, neural networks are not new. Most of these concepts are over half a century old. The US postal services, for instance, started using neural nets to automate zip code detection in the 1990s. However, it is only recently that they have come into wider use.
We employed a type of neural network called Convolutional Neural Networks (CNN). These can detect the various features in the image and map them to a particular class.
Architecture
Now came the question of which neural network architecture to use. We could either employ transfer learning, that is, fine-tune a previously trained network such as ResNet, or train the network from scratch.
Since our use case was relatively straightforward and the image features that we aimed to detect were simple strokes, transfer learning would have been overkill and would have most likely caused overfitting. Hence we decided to use a simple CNN architecture.
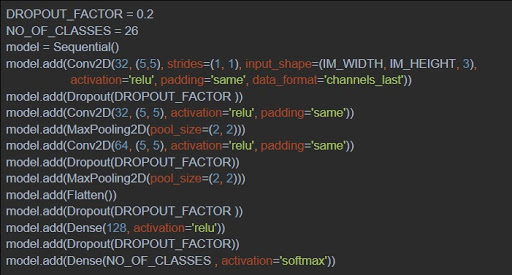
We went with a 3 layer CNN along with a dropout factor of 0.2 as our model architecture. Dropout is a technique by which some connections in the net are cut during training so that no single portion of the net learns features all by itself. It usually leads to better training accuracy. We also trained three such networks, one for handling digits, one for alphabets, and one for alphanumeric data.
Along with the CNN layers, we used a flattening layer so that the features can be fed to a Dense classifier. In the end, a couple of dense layers with Softmax activation were used to get the probability of each class. We then selected the character class with the highest probability as the predicted label for each image.
Data for Model Training
Conventional image processing approaches consistently fall short of achieving expected results and they are better only if the images are free of deformities. If we employ machine learning, we only have to label the training data. Machine learning models are better at handling wide variations in the images.
The machine learning model learns what constitutes a character. Relationships between various lines and curves in the image help the model decide what character to predict. Thus it can handle large variations in writing styles.
To train such a model, we needed a huge dataset with maximum possible character variations. Our search for a diverse dataset led us to the IAM dataset. It is a public domain dataset that contains the handwriting of 657 unique users. The characters were extracted from written paragraphs of text and annotated.
We also printed some blank forms and made our colleagues fill them out for generating a reliable test dataset. This dataset had around 5000 images per character class.
Feedback Training
Since deep learning-based solutions aren’t perfect, there is always scope for feedback learning. The end users have to correct the predictions and these corrections will be used to create a new dataset that can be further used to fine-tune the model. This approach in the long term will fix most of the errors encountered by the system.
The feedback training using this dataset is different from the initial training. Here, the model is run with a reduced learning rate. This ensures that only small adjustments will be made to the internal weights of the model.
Once the feedback training is complete, the model can be evaluated against our test dataset and the model with the highest test accuracy will be made the default from then on. We ran this training job once or twice a month during off times to minimize downtime.
Conclusion
When we tested the system in house, we were able to achieve a character recognition accuracy of over 95% on the forms. However, this is still some way off the fully automated target that we want to achieve. The feedback learning system we employed will help improve the results over time and might make it possible for the client to run the system without human oversight.
